
In questo articolo, descriviamo passo dopo passo come applicare il NLP (Natural Language Processing) agli annunci di lavoro.
Se vuoi vedere un esempio pratico usando il pacchetto Natural Language Toolkit (NLTK) con codice Python, questo articolo è per te.
Iniziamo subito.
Sommario
Preparazione: Scraping dei dati
In questo articolo abbiamo bisogno di un dataset iniziale. Per i nostri scopi abbiamo creato un dataset con gli annunci di lavoro per “data scientist” per 8 diverse città tramite un web scraping da Indeed.com. Abbiamo scaricato i dati in file separati per ciascuna città.
Le 8 città incluse in questa analisi sono Boston, Chicago, Los Angeles, Montreal, New York, San Francisco, Toronto e Vancouver . Le variabili sono job_title, company, location e job_description.
Non entriamo nei dettagli di questo processo di web scraping.
Ora siamo pronti per la vera analisi! Da questi dati vogliamo estrarre le informazioni relative agli strumenti popolari, le competenze e l’istruzione minima richiesti dai datori di lavoro .
Step #1: Caricamento e pulizia dei dati
Per prima cosa, carichiamo e unifichiamo i file di dati delle 8 città usando Python.
from collections import Counter
import nltk
import string
from nltk.tokenize import word_tokenize
import math
from plotly import __version__
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
import plotly.graph_objs as go
init_notebook_mode(connected=True)
# load in the data.
df_list = []
cities = ['boston', 'chicago', 'la', 'montreal', 'ny', 'sf', 'toronto', 'vancouver']
for city in cities:
df_tmp = pd.read_pickle('data_scientist_{}.pkl'.format(city))
df_tmp['city'] = city
df_list.append(df_tmp)
df = pd.concat(df_list).reset_index(drop=True)
# make the city names nicer.
msk = df['city'] == 'la'
df.loc[msk, 'city'] = 'los angeles'
msk = df['city'] == 'ny'
df.loc[msk, 'city'] = 'new york'
msk = df['city'] == 'sf'
df.loc[msk, 'city'] = 'san francisco'
Rimuoviamo le righe/gli annunci di lavoro duplicati con le stesse caratteristiche di job_title, job_description e city.
# If it's the same job description in the same city, for the same job title, we consider it duplicate.
print(df.shape)
df = df.drop_duplicates(subset=['job_description', 'city', 'job_title'])
print(df.shape)

Step #2: Formare gli elenchi di parole chiave
Prima di cercare nelle descrizioni dei lavori, abbiamo bisogno di elenchi di parole chiave che rappresentino gli strumenti / le competenze / i titoli di studio.
Per questa analisi, utilizziamo un semplice approccio per creare le liste. Gli elenchi si basano sul nostro giudizio e sul contenuto degli annunci di lavoro. È possibile utilizzare approcci più avanzati per attività più complicate di questa.
Per l’elenco delle parole chiave degli strumenti , inizialmente creiamo un elenco basato sulla nostra conoscenza della scienza dei dati. Sappiamo che gli strumenti popolari per i data scientist includono Python, R, Hadoop, Spark e altri. Abbiamo una discreta conoscenza del settore. Quindi questo elenco iniziale è esaustivo ed include i principali strumenti menzionati negli annunci di lavoro.
Quindi esaminiamo annunci di lavoro in modo casuale e aggiungiamo strumenti che non sono ancora nell’elenco. Spesso queste nuove parole chiave ci ricordano di aggiungere anche altri strumenti correlati.
Dopo questo processo, abbiamo un elenco di parole chiave che copre la maggior parte degli strumenti menzionati negli annunci di lavoro.
Successivamente, separiamo le parole chiave in un elenco di parole singole e un elenco di più parole. Abbiamo bisogno di abbinare questi due elenchi con la descrizione del lavoro tramite diverse logiche e metodologie.
Con semplici corrispondenze di stringhe, la parola chiave composta da più parole è spesso unica ed è facile da identificare nella descrizione della posizione lavorativa.
La parola chiave di una sola parola, come “c”, si riferisce al linguaggio di programmazione C. Ma “c” è anche una lettera comune che viene usata in molte parole tra cui “can”, “clustering”. Dobbiamo elaborarli ulteriormente (attraverso la tokenizzazione) in modo che corrispondano solo quando è presente una sola lettera “c” nelle descrizioni dei lavori.
Di seguito sono riportati i nostri elenchi di parole chiave per strumenti codificati in Python.
# got these keywords by looking at some examples and using existing knowledge.
tool_keywords1 = ['python', 'pytorch', 'sql', 'mxnet', 'mlflow', 'einstein', 'theano', 'pyspark', 'solr', 'mahout',
'cassandra', 'aws', 'powerpoint', 'spark', 'pig', 'sas', 'java', 'nosql', 'docker', 'salesforce', 'scala', 'r', 'c', 'c++', 'net', 'tableau', 'pandas', 'scikitlearn', 'sklearn', 'matlab', 'scala', 'keras', 'tensorflow', 'clojure', 'caffe', 'scipy', 'numpy', 'matplotlib', 'vba', 'spss', 'linux', 'azure', 'cloud', 'gcp', 'mongodb', 'mysql', 'oracle', 'redshift', 'snowflake', 'kafka', 'javascript', 'qlik', 'jupyter', 'perl', 'bigquery', 'unix', 'react', 'scikit', 'powerbi', 's3', 'ec2', 'lambda', 'ssrs', 'kubernetes', 'hana', 'spacy', 'tf', 'django', 'sagemaker', 'seaborn', 'mllib', 'github', 'git', 'elasticsearch', 'splunk', 'airflow', 'looker', 'rapidminer', 'birt', 'pentaho', 'jquery', 'nodejs', 'd3', 'plotly', 'bokeh', 'xgboost', 'rstudio', 'shiny', 'dash', 'h20', 'h2o', 'hadoop', 'mapreduce', 'hive', 'cognos', 'angular', 'nltk', 'flask', 'node', 'firebase', 'bigtable', 'rust', 'php', 'cntk', 'lightgbm', 'kubeflow', 'rpython', 'unixlinux', 'postgressql', 'postgresql', 'postgres', 'hbase', 'dask', 'ruby', 'julia', 'tensor',
# added r packages doesn't seem to impact the result
'dplyr', 'ggplot2', 'esquisse', 'bioconductor', 'shiny' , 'lubridate','knitr','mlr', 'quanteda', 'dt', 'rcrawler', 'caret', 'rmarkdown', 'leaflet', 'janitor', 'ggvis', 'plotly', 'rcharts', 'rbokeh', 'broom', 'stringr', 'magrittr', 'slidify', 'rvest', 'rmysql', 'rsqlite', 'prophet', 'glmnet', 'text2vec', 'snowballc', 'quantmod', 'rstan', 'swirl', 'datasciencer']
# another set of keywords that are longer than one word.
tool_keywords2 = set(['amazon web services', 'google cloud', 'sql server'])
Otteniamo elenchi di parole chiave per le abilità seguendo un processo simile a quello degli strumenti.
# hard skills/knowledge required.
skill_keywords1 = set(['statistics', 'cleansing', 'chatbot', 'cleaning', 'blockchain', 'causality', 'correlation', 'bandit', 'anomaly', 'kpi', 'dashboard', 'geospatial', 'ocr', 'econometrics', 'pca', 'gis', 'svm', 'svd', 'tuning', 'hyperparameter', 'hypothesis', 'salesforcecom', 'segmentation', 'biostatistics', 'unsupervised', 'supervised', 'exploratory', 'recommender', 'recommendations', 'research', 'sequencing', 'probability', 'reinforcement', 'graph', 'bioinformatics', 'chi', 'knn', 'outlier', 'etl', 'normalization', 'classification', 'optimizing', 'prediction', 'forecasting', 'clustering', 'cluster', 'optimization', 'visualization', 'nlp', 'c#', 'regression', 'logistic', 'nn', 'cnn', 'glm', 'rnn', 'lstm', 'gbm', 'boosting', 'recurrent', 'convolutional', 'bayesian', 'bayes'])
# another set of keywords that are longer than one word.
skill_keywords2 = set(['random forest', 'natural language processing', 'machine learning', 'decision tree', 'deep learning', 'experimental design', 'time series', 'nearest neighbors', 'neural network', 'support vector machine', 'computer vision', 'machine vision', 'dimensionality reduction', 'text analytics', 'power bi', 'a/b testing', 'ab testing', 'chat bot', 'data mining'])
Per il titolo di studio, utilizziamo una procedura diversa.
Poiché stiamo cercando minimo il livello di istruzione richiesto, abbiamo bisogno di un valore numerico per classificare il grado di istruzione. Ad esempio, usiamo 1 per rappresentare “bachelor” o “studente”, 2 per rappresentare “master” o “laureato”, e così via.
In questo modo, abbiamo una graduatoria dei titoli in base a numeri da 1 a 4. Più alto è il numero, più alto è il livello di istruzione.
degree_dict = {'bs': 1, 'bachelor': 1, 'undergraduate': 1,
'master': 2, 'graduate': 2, 'mba': 2.5,
'phd': 3, 'ph.d': 3, 'ba': 1, 'ma': 2,
'postdoctoral': 4, 'postdoc': 4, 'doctorate': 3}
degree_dict2 = {'advanced degree': 2, 'ms or': 2, 'ms degree': 2, '4 year degree': 1, 'bs/': 1, 'ba/': 1,
'4-year degree': 1, 'b.s.': 1, 'm.s.': 2, 'm.s': 2, 'b.s': 1, 'phd/': 3, 'ph.d.': 3, 'ms/': 2,
'm.s/': 2, 'm.s./': 2, 'msc/': 2, 'master/': 2, 'master\'s/': 2, 'bachelor\s/': 1}
degree_keywords2 = set(degree_dict2.keys())
Step #3: Razionalizzazione delle descrizioni dei lavori utilizzando le tecniche NLP
In questo passaggio, semplifichiamo il testo della descrizione del lavoro. Rendiamo il testo più facile da capire dagli algoritmi; e quindi più efficiente per abbinare il testo con gli elenchi di parole chiave.
La funzione job_description nel nostro set di dati è simile a questa.
df['job_description'].iloc[12]

Tokenizzazione delle descrizioni dei lavori
La tokenizzazione è un processo di analisi delle stringhe di testo in diverse sezioni (token). Questo passaggio è necessario perchè gli algoritmi comprendono meglio il testo tokenizzato. Dobbiamo dividere in modo esplicito la stringa di testo della descrizione del lavoro in diversi token (parole) con delimitatori come lo spazio (” “). Usiamo la funzioneword_tokenize per gestire questo compito.
word_tokenize(df['job_description'].iloc[12])
Dopo questo processo, la stringa di testo della descrizione del lavoro viene partizionata in token (parole), come nella seguente figura. Gli algoritmi possono leggere ed elaborare più facilmente questi token.
Ad esempio, la parola chiave di una sola parola “c” può corrispondere solo con i token (parole) “c”, piuttosto che con altre parole “can” o “clustering”.

Parts of Speech (POS) che contrassegnano le descrizioni dei lavori
Le descrizioni dei lavori sono spesso lunghe. Vogliamo mantenere le parole che sono informative per la nostra analisi filtrando le altre. Utilizziamo la codifica POS per raggiungere questo obiettivo.
La codifica POS è un metodo NLP per etichettare se una parola è un sostantivo, aggettivo, verbo, ecc. Wikipedia lo spiega bene:
La codifica POS è il processo di contrassegnare una parola in un testo (corpus) come corrispondente a una parte particolare del discorso, in base sia alla sua definizione che al suo contesto, ovvero la sua relazione con parole adiacenti e correlate in una frase, frase o paragrafo. Una forma semplificata di questo è comunemente insegnata ai bambini in età scolare, nell’identificazione di parole come nomi, verbi, aggettivi, avverbi, ecc.
Grazie a NLTK, possiamo usare questo metodo in Python.
Applicando questa tecnica alle liste di parole chiave, possiamo trovare dei tag relativi alla nostra analisi.
Di seguito codifichiamo con POS l’elenco di parole chiave per gli strumenti.
from nltk import pos_tag
from nltk.stem import PorterStemmer
pos_tag(tool_keywords1)
Diverse combinazioni di lettere rappresentano i tag. Ad esempio, NN sta per nomi e parole singolari come “python”, JJ sta per aggettivi come “big”. L’elenco completo delle rappresentazioni è disponibile in questo sito.
Come possiamo vedere, il tagger non è perfetto. Ad esempio, “sql” è etichettato come “JJ” — aggettivo. Ma è ancora abbastanza buono per aiutarci a filtrare parole utili.

Usiamo questo elenco di tag di tutte le parole chiave come filtro per le descrizioni dei lavori. Conserviamo solo le parole delle descrizioni dei lavori che hanno gli stessi tag di parole chiave. Ad esempio, manterremmo le parole delle descrizioni dei lavori con i tag “NN” e “JJ”. In questo modo, filtriamo le parole dalle descrizioni del lavoro come “il”, “allora” che non sono informative per la nostra analisi.
In questa fase, abbiamo semplificato le descrizioni dei lavori che vengono tokenizzate e abbreviate.
Ora dobbiamo solo elaborarli un po’ di più.
Step #4: Elaborazione finale delle parole chiave e delle descrizioni dei lavori
In questo passaggio, elaboriamo ulteriormente sia gli elenchi di parole chiave che le descrizioni dei lavori.
Stemming delle parole
Lo stemming delle parole è il processo di riduzione delle parole flesse (o talvolta derivate) alla loro forma base o radice della parola, generalmente una forma di parola scritta.
Il processo di stemming consente agli algoritmi di identificare le parole con la stessa radice nonostante il loro aspetto diverso. In questo modo, possiamo abbinare le parole purché abbiano la stessa radice. Ad esempio, le parole “modelli”, “modellare” hanno entrambe la stessa radice “modello”.
Disponiamo sia degli elenchi di parole chiave che delle descrizioni dei lavori semplificate.
Formattazione minuscola delle parole
Infine, standardizziamo tutte le parole mettendole in minuscolo. Dobbiamo formattare in minuscolo le descrizioni dei lavori poiché gli elenchi di parole chiave sono costruiti in minuscolo.
Come accennato nelle sezioni precedenti, il codice Python utilizzato nelle procedure precedenti è riportato di seguito.
from nltk import pos_tag
from nltk.stem import PorterStemmer
ps = PorterStemmer()
# process the job description.
def prepare_job_desc(desc):
# tokenize description.
tokens = word_tokenize(desc)
# Parts of speech (POS) tag tokens.
token_tag = pos_tag(tokens)
# Only include some of the POS tags.
include_tags = ['VBN', 'VBD', 'JJ', 'JJS', 'JJR', 'CD', 'NN', 'NNS', 'NNP', 'NNPS']
filtered_tokens = [tok for tok, tag in token_tag if tag in include_tags]
# stem words.
stemmed_tokens = [ps.stem(tok).lower() for tok in filtered_tokens]
return set(stemmed_tokens)
df['job_description_word_set'] = df['job_description'].map(prepare_job_desc)
# process the keywords
tool_keywords1_set = set([ps.stem(tok) for tok in tool_keywords1]) # stem the keywords (since the job description is also stemmed.)
tool_keywords1_dict = {ps.stem(tok):tok for tok in tool_keywords1} # use this dictionary to revert the stemmed words back to the original.
skill_keywords1_set = set([ps.stem(tok) for tok in skill_keywords1])
skill_keywords1_dict = {ps.stem(tok):tok for tok in skill_keywords1}
degree_keywords1_set = set([ps.stem(tok) for tok in degree_dict.keys()])
degree_keywords1_dict = {ps.stem(tok):tok for tok in degree_dict.keys()}
Ora rimangono solo le parole (token) nelle descrizioni dei lavori che sono legate alla nostra analisi.
Di seguito è riportato un esempio finale delle descrizione dei lavori.
df['job_description_word_set'].iloc[10]

Step #5: Abbinare le parole chiave e le descrizioni del lavoro
Per vedere se una descrizione di lavoro menziona parole chiave specifiche, abbiniamo gli elenchi di parole chiave e le descrizioni di lavoro semplificate finali.
Strumenti/Abilità
Come ricorderete, abbiamo creato due tipi di elenchi di parole chiave: l’elenco di parole singole e l’elenco di più parole. Per le parole chiave di una sola parola, abbiniamo ciascuna parola chiave alla descrizione del lavoro mediante la funzione di intersezione impostata. Per le parole chiave composte da più parole, controlliamo se sono sottostringhe delle descrizioni dei lavori.
Formazione scolastica
Per il livello di istruzione, utilizziamo lo stesso metodo degli strumenti/abilità per abbinare le parole chiave. Tuttavia, teniamo traccia solo del livello minimo.
Ad esempio, quando le parole chiave “bachelor” e “master” esistono entrambe in una descrizione del lavoro, la laurea è l’istruzione minima richiesta per questo lavoro.
Il codice Python con maggiori dettagli è di seguito.
tool_list = []
skill_list = []
degree_list = []
msk = df['city'] != '' # just in case you want to filter the data.
num_postings = len(df[msk].index)
for i in range(num_postings):
job_desc = df[msk].iloc[i]['job_description'].lower()
job_desc_set = df[msk].iloc[i]['job_description_word_set']
# check if the keywords are in the job description. Look for exact match by token.
tool_words = tool_keywords1_set.intersection(job_desc_set)
skill_words = skill_keywords1_set.intersection(job_desc_set)
degree_words = degree_keywords1_set.intersection(job_desc_set)
# check if longer keywords (more than one word) are in the job description. Match by substring.
j = 0
for tool_keyword2 in tool_keywords2:
# tool keywords.
if tool_keyword2 in job_desc:
tool_list.append(tool_keyword2)
j += 1
k = 0
for skill_keyword2 in skill_keywords2:
# skill keywords.
if skill_keyword2 in job_desc:
skill_list.append(skill_keyword2)
k += 1
# search for the minimum education.
min_education_level = 999
for degree_word in degree_words:
level = degree_dict[degree_keywords1_dict[degree_word]]
min_education_level = min(min_education_level, level)
for degree_keyword2 in degree_keywords2:
# longer keywords. Match by substring.
if degree_keyword2 in job_desc:
level = degree_dict2[degree_keyword2]
min_education_level = min(min_education_level, level)
# label the job descriptions without any tool keywords.
if len(tool_words) == 0 and j == 0:
tool_list.append('nothing specified')
# label the job descriptions without any skill keywords.
if len(skill_words) == 0 and k == 0:
skill_list.append('nothing specified')
# If none of the keywords were found, but the word degree is present, then assume it's a bachelors level.
if min_education_level > 500:
if 'degree' in job_desc:
min_education_level = 1
tool_list += list(tool_words)
skill_list += list(skill_words)
degree_list.append(min_education_level)
Step #6: Visualizzazione dei risultati
Riassumiamo i risultati con grafici a barre.
Per ogni particolare parola chiave di strumenti/abilità/livelli di istruzione, contiamo il numero di descrizioni di lavoro che corrispondono ad esse. Calcoliamo anche la loro percentuale tra tutte le descrizioni dei lavori.
Per gli elenchi di strumenti e abilità, presentiamo solo i primi 50 più popolari. Per il livello di istruzione, li riassumiamo in base al livello minimo richiesto.
Il codice Python dettagliato è di seguito.
I strumenti più richiesti
# create the list of tools.
df_tool = pd.DataFrame(data={'cnt': tool_list})
df_tool = df_tool.replace(tool_keywords1_dict)
# group some of the categories together.
msk = df_tool['cnt'] == 'h20'
df_tool.loc[msk, 'cnt'] = 'h2o'
msk = df_tool['cnt'] == 'aws'
df_tool.loc[msk, 'cnt'] = 'amazon web services'
msk = df_tool['cnt'] == 'gcp'
df_tool.loc[msk, 'cnt'] = 'google cloud'
msk = df_tool['cnt'] == 'github'
df_tool.loc[msk, 'cnt'] = 'git'
msk = df_tool['cnt'] == 'postgressql'
df_tool.loc[msk, 'cnt'] = 'postgres'
msk = df_tool['cnt'] == 'tensor'
df_tool.loc[msk, 'cnt'] = 'tensorflow'
df_tool_top50 = df_tool['cnt'].value_counts().reset_index().rename(columns={'index': 'tool'}).iloc[:50]
# visualize the tools.
layout = dict(
title='Tools For Data Scientists',
yaxis=dict(
title='% of job postings',
tickformat=',.0%',
)
)
fig = go.Figure(layout=layout)
fig.add_trace(go.Bar(
x=df_tool_top50['tool'],
y=df_tool_top50['cnt']/num_postings
))
iplot(fig)
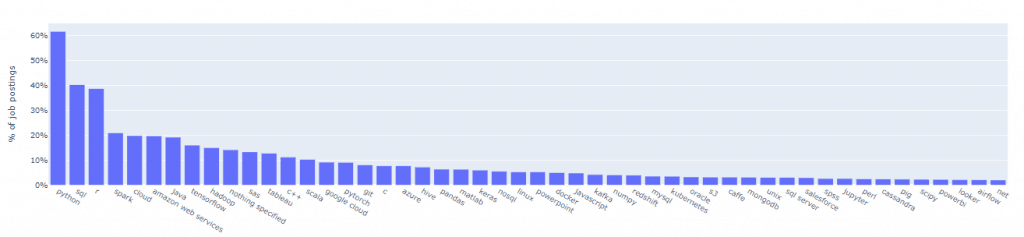
Le competenze più richieste
# create the list of skills/knowledge.
df_skills = pd.DataFrame(data={'cnt': skill_list})
df_skills = df_skills.replace(skill_keywords1_dict)
# group some of the categories together.
msk = df_skills['cnt'] == 'nlp'
df_skills.loc[msk, 'cnt'] = 'natural language processing'
msk = df_skills['cnt'] == 'convolutional'
df_skills.loc[msk, 'cnt'] = 'convolutional neural network'
msk = df_skills['cnt'] == 'cnn'
df_skills.loc[msk, 'cnt'] = 'convolutional neural network'
msk = df_skills['cnt'] == 'recurrent'
df_skills.loc[msk, 'cnt'] = 'recurrent neural network'
msk = df_skills['cnt'] == 'rnn'
df_skills.loc[msk, 'cnt'] = 'recurrent neural network'
msk = df_skills['cnt'] == 'knn'
df_skills.loc[msk, 'cnt'] = 'nearest neighbors'
msk = df_skills['cnt'] == 'svm'
df_skills.loc[msk, 'cnt'] = 'support vector machine'
msk = df_skills['cnt'] == 'machine vision'
df_skills.loc[msk, 'cnt'] = 'computer vision'
msk = df_skills['cnt'] == 'ab testing'
df_skills.loc[msk, 'cnt'] = 'a/b testing'
df_skills_top50 = df_skills['cnt'].value_counts().reset_index().rename(columns={'index': 'skill'}).iloc[:50]
# visualize the skills.
layout = dict(
title='Skills For Data Scientists',
yaxis=dict(
title='% of job postings',
tickformat=',.0%',
)
)
fig = go.Figure(layout=layout)
fig.add_trace(go.Bar(
x=df_skills_top50['skill'],
y=df_skills_top50['cnt']/num_postings
))
iplot(fig)
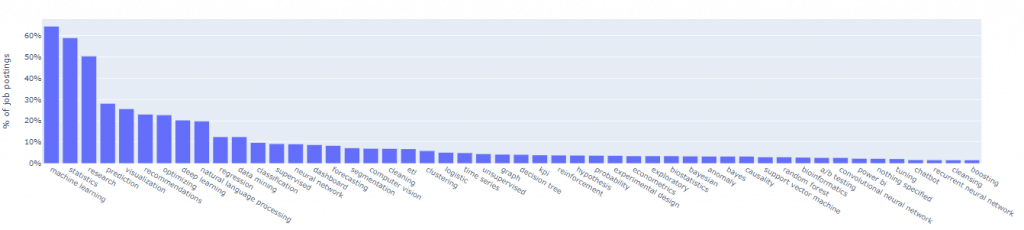
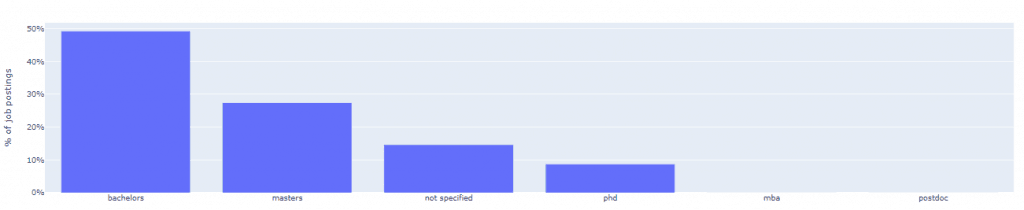
Istruzione minima richiesta
# create the list of degree.
df_degrees = pd.DataFrame(data={'cnt': degree_list})
df_degrees['degree_type'] = ''
msk = df_degrees['cnt'] == 1
df_degrees.loc[msk, 'degree_type'] = 'bachelors'
msk = df_degrees['cnt'] == 2
df_degrees.loc[msk, 'degree_type'] = 'masters'
msk = df_degrees['cnt'] == 3
df_degrees.loc[msk, 'degree_type'] = 'phd'
msk = df_degrees['cnt'] == 4
df_degrees.loc[msk, 'degree_type'] = 'postdoc'
msk = df_degrees['cnt'] == 2.5
df_degrees.loc[msk, 'degree_type'] = 'mba'
msk = df_degrees['cnt'] > 500
df_degrees.loc[msk, 'degree_type'] = 'not specified'
df_degree_cnt = df_degrees['degree_type'].value_counts().reset_index().rename(columns={'index': 'degree'}).iloc[:50]
# visualize the degrees.
layout = dict(
title='Minimum Education For Data Scientists',
yaxis=dict(
title='% of job postings',
tickformat=',.0%',
)
)
fig = go.Figure(layout=layout)
fig.add_trace(go.Bar(
x=df_degree_cnt['degree'],
y=df_degree_cnt['degree_type']/num_postings
))
iplot(fig)
Ce l’abbiamo fatta !
Spero che questo articolo sia stato utile. Lascia un commento per farmi sapere i tuoi dubbi e suggerimenti.