
In questo post introduciamo Apache Airflow, un sistema di gestione del flusso di lavoro sviluppato da Airbnb.
Apache Airflow permette ovviamente di creare pipeline ETL per automatizzare le cose, ma le sue funzionalità permettono di implementare molti altri scenari dove è necessario eseguire attività in un determinato ordine, almeno una volta o periodicamente. Ad esempio:
- Monitoraggio dei Cron
- Trasferire dati da un luogo all’altro.
- Automatizzare le operazioni DevOps.
- Recuperare periodicamente i dati dai siti Web ed aggiornare un database.
- Elaborazione dei dati per sistemi complessi.
- Pipeline di machine learning.
Le possibilità sono infinite.
Prima di vedere l’implementazione di Airflow nei nostri sistemi, descriviamo cosa effettivamente è Airflow e delle sue terminologie.
Che cos’è il Airflow?
Dal sito web:
Airflow è una piattaforma per creare, pianificare e monitorare i flussi di lavoro in modo programmatico.
Utilizza Airflow per creare flussi di lavoro come grafici aciclici diretti (DAG) di attività. Lo scheduler di Airflow esegue le tue attività su una serie di worker, seguendo le dipendenze specificate. Le ricche utilità della riga di comando semplificano l’esecuzione di interventi complessi sui DAG. La ricca interfaccia utente semplifica la visualizzazione delle pipeline in esecuzione in produzione, il monitoraggio dei progressi e la risoluzione dei problemi quando necessario.
Fondamentalmente, aiuta ad automatizzare gli script per eseguire attività. Airflow è basato su Python ma puoi eseguire un programma indipendentemente dal linguaggio. Ad esempio, la prima fase del flusso di lavoro deve eseguire un programma basato su C++ per eseguire l’analisi delle immagini e quindi un programma basato su Python per trasferire tali informazioni su S3. Le possibilità sono infinite.
Cos’è Dag?
Da Wikipedia
In matematica e informatica, un grafo aciclico diretto (DAG /ˈdæɡ/, è un grafo diretto finito senza cicli diretti. Cioè, consiste di un numero finito di vertici e spigoli, con ogni spigolo diretto da un vertice all’altro, in modo tale che non c’è modo di iniziare da nessun vertice v e seguire una sequenza di spigoli coerentemente diretta che alla fine torna nuovamente a v . Equivalentemente, un DAG è un grafo diretto che ha un ordinamento topologico, una sequenza di vertici tale che ogni arco è diretto da prima a dopo nella sequenza.
Proviamo a spiegarlo in parole semplici: puoi essere solo figlio di tuo padre ma non viceversa. OK, è un esempio zoppo o strano, ma non sono riuscito a trovare un esempio migliore per spiegare un ciclo diretto .
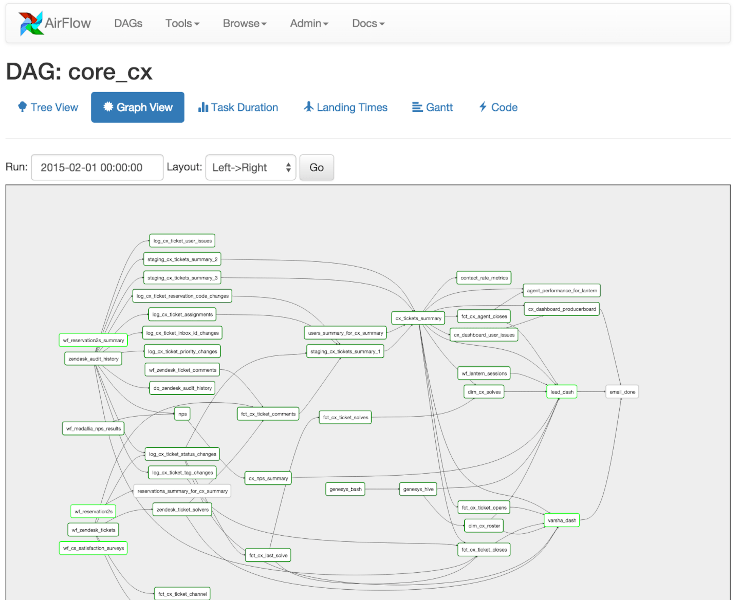
In Airflow tutti i flussi di lavoro sono DAG. Un Dag è composto da operatori. Un operatore definisce un’attività individuale che deve essere eseguita. Sono disponibili diversi tipi di operatori (come indicato sul sito Web Airflow):
BashOperator– esegue un comando bashPythonOperator– richiama un’arbitraria funzione PythonEmailOperator– invia un’e-mailSimpleHttpOperator– invia una richiesta HTTPMySqlOperator,SqliteOperator,PostgresOperator,MsSqlOperator,OracleOperator,JdbcOperator, ecc. – esegue un comando SQLSensor– attende un certo tempo, file, record di un database, chiave S3, ecc…
Possiamo anche trovare un operatore personalizzato secondo specifiche esigenze.
Installazione e configurazione
Ariflow è basato su Python. Il modo migliore per installarlo è tramite lo strumento pip.
pip install apache-airflow
Per verificare se è stato installato, eseguiamo il comando airflow version e otteniamo qualcosa del tipo:
[2020-12-02 15:59:23,880] {__init__.py:51} INFO - Using executor SequentialExecutor
____________ _____________
____ |__( )_________ __/__ /________ __
____ /| |_ /__ ___/_ /_ __ /_ __ \_ | /| / /
___ ___ | / _ / _ __/ _ / / /_/ /_ |/ |/ /
_/_/ |_/_/ /_/ /_/ /_/ \____/____/|__/
v1.10.0
You will need to install mysqlclient as well to incorporate MySQL in your workflows. It is optional though.
Inoltre possiamo anche installare mysqlclient per incorporare MySQL nei flussi di lavoro. È facoltativo e possiamo scegliere un diverso database, come postgresql, SQlite, ecc…
pip install mysqlclient
Prima di iniziare, è necessario creare una cartella ed impostala come AIRFLOW_HOME. Nel nostro caso è “airflow_home”. Una volta creata, eseguiamo il comando export per impostare la home nelle variabili d’ambiente.
export AIRFLOW_HOME='pwd' airflow_home
E’ necessario assicurarsi di essere nella directory padre di “airflow_home” prima di eseguire il comando export. Inoltre all’interno di “airflow_home” è necessario creare un’altra cartella per conservare i DAG, chiamata dags.
Se si imposta load_examples=False, gli esempi predefiniti non verranno caricati sull’interfaccia Web.
Ora dobbiamo eseguire il seguente comando all’interno della cartella “airflow_home”.
airflow db init
Questo comando crea i file airflow.cfg e unitests.cfg
In particolare airflow.db è un file SQLite per memorizzare tutta la configurazione relativa ai flussi di lavoro di esecuzione. airflow.cfg è quello di memorizzare tutte le impostazioni iniziali per gestire i wrokflow in esecuzione.
In questo file, è presente il parametro sql_alchemy_conn con il valore ../airflow_home/airflow.db.
Possiamo usare MySQL, ma per ora, seguiamo le impostazioni di base.
Airflow WebServer
Fin qui tutto bene, ora senza perdere tempo avviamo il web server.
airflow webserver
Quando si avvia il webserver si ha una stampa simile a quanto segue:
2020-12-02 22:36:24,943] {__init__.py:51} INFO - Using executor SequentialExecutor
/anaconda3/anaconda/lib/python3.6/site-packages/airflow/bin/cli.py:1595:
DeprecationWarning: The celeryd_concurrency option in [celery]
has been renamed to worker_concurrency - the old setting has been used,
but please update your config. default=conf.get('celery', 'worker_concurrency')),
____________ _____________
____ |__( )_________ __/__ /________ __
____ /| |_ /__ ___/_ /_ __ /_ __ \_ | /| / /
___ ___ | / _ / _ __/ _ / / /_/ /_ |/ |/ /
_/_/ |_/_/ /_/ /_/ /_/ \____/____/|__/
v1.10.0
[2020-12-03 14:21:42,340] {__init__.py:57} INFO - Using executor SequentialExecutor
____________ _____________
____ |__( )_________ __/__ /________ __
____ /| |_ /__ ___/_ /_ __ /_ __ \_ | /| / /
___ ___ | / _ / _ __/ _ / / /_/ /_ |/ |/ /
_/_/ |_/_/ /_/ /_/ /_/ \____/____/|__/
/anaconda3/anaconda/lib/python3.6/site-packages/flask/exthook.py:71:
ExtDeprecationWarning: Importing flask.ext.cache is deprecated, use flask_cache instead.
.format(x=modname), ExtDeprecationWarning
[2020-12-03 14:21:43,119] [48995] {models.py:167} INFO -
Filling up the DagBag from /Development/airflow_home/dags
Running the Gunicorn Server with:
Workers: 4 sync
Host: 0.0.0.0:8080
Ora, visitiamo la pagina 0.0.0.0:8080 e otteniamo la seguente schermata:
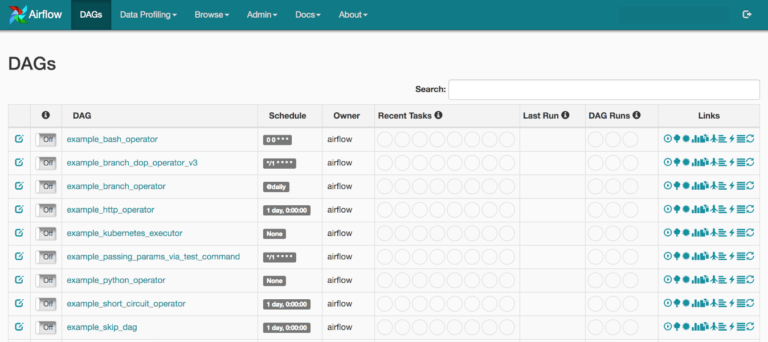
Qui possiamo vedere una serie di voci. Queste sono gli esempi forniti con l’installazione Airflow. Si possono disattivarli modificando il file airflow.cfg e impostando il parametro load_examples su FALSE.
Le DAG Runs indicano quante volte è stato eseguito un determinato DAG. Recent Tasks indica quale attività tra molte attività all’interno di un DAG è attualmente in esecuzione e qual è il suo stato. Lo schedule è simile a quello che si usa quando si pianifica un Cron, quindi al momento non ha bisogno di approfondimenti. Lo Schedule è responsabile dell’ora in cui un determinato DAG dovrebbe essere attivato.
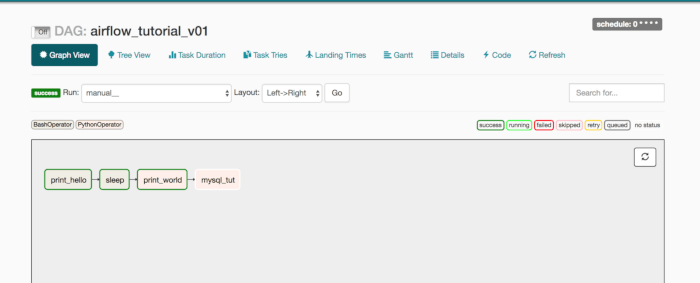
Qui sopra veidamo lo screenshot di un DAG creato ed eseguito in precedenza. Le caselle rettangolari rappresentano un’attività (o Task). In alto a destra si possono vedere caselle di diverso colore, denominate: success, running, failed ecc. Questi sono gli stati che un DAG può assumere.
Nell’immagine sopra è possibile che tutte le caselle abbiano un bordo verde, tuttavia, se non siamo sicuri è sufficiente muovere il mouse sopra uno stato success e si evidenziano i task in quello stato, come nell’immagine seguente:
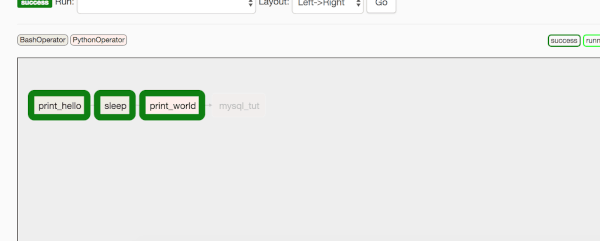
Da notare che il colore di sfondo/riempimento di queste caselle è verde e canna. In alto a sinistra del pannello grigio, puoi vedere perché sono ci sono tali colori, questi colori di sfondo rappresentano i diversi tipi di operatori utilizzati in questo DAG. In questo caso, stiamo usando BashOperator e PythonOperator.
Esempio di base
Vediamo ora un esempio di base per descrivere il funzionamento di Airflow. Nella cartella dags, che è stata precedentemente creata in airflow_home, creeremo il nostro primo DAG di esempio. In pratica si deve creare un file denominato, ad esempio,my_simple_dag.py.
La prima cosa da fare dopo le importazioni è scrivere le routine che serviranno come task per gli operatori. Useremo una miscela di BashOperator e PythonOperator.
import datetime as dt
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
def greet():
print('Writing in file')
with open('path/to/file/greet.txt', 'a+', encoding='utf8') as f:
now = dt.datetime.now()
t = now.strftime("%Y-%m-%d %H:%M")
f.write(str(t) + '\n')
return 'Greeted'
def respond():
return 'Greet Responded Again'
default_args e creare un’istanza DAG.
default_args = {
'owner': 'airflow',
'start_date': dt.datetime(2020, 12, 03, 11, 00, 00),
'concurrency': 1,
'retries': 0
}
Nella variabile default_args si definisco una serie di parametri.
start_date indica quando questo DAG dovrebbe iniziare a eseguire il flusso di lavoro. Questo start_date potrebbe appartenere al passato. Nel mio caso, è il 3 dicembre alle 11:00 UTC. Questa data è già passata per me perché ora sono già le 11:15 UTC. Puoi sempre modificare questo parametro all’interno del file airflow.cfg e impostare il tuo fuso orario locale. Per ora, possiamo anche lasciare UTC. Nel caso in cui tu sia ancora curioso di sapere che ora viene utilizzata da Airflow, controlla in alto a destra nell’interfaccia utente Web di Airflow, dovresti vedere qualcosa di simile a quello indicato di seguito. Puoi usarlo come riferimento per pianificare le tue attività.
Il parametro retries tenta di eseguire il DAG X un numero di volte in caso di mancata esecuzione. Il parametro concurrency aiuta a determinare il numero di processi da utilizzare per l’esecuzione di più DAG. Per esempio, il DAG deve eseguire 4 istanze del passato, chiamati anche come Backfill , con un intervallo di 10 minuti (vedremo questo argomento complesso a breve) ed è stata impostata concurrency pari a 2, quindi 2 DAG sono lanciati nello stesso momento ed sono eseguite i task previsto in esse. Se hai già implementato multiprocessing in Python, dovresti facilmente capire il funzionamento.
with DAG('my_simple_dag',
default_args=default_args,
schedule_interval='*/10 * * * *',
) as dag:
opr_hello = BashOperator(task_id='say_Hi',
bash_command='echo "Hi!!"')
opr_greet = PythonOperator(task_id='greet',
python_callable=greet)
opr_sleep = BashOperator(task_id='sleep_me',
bash_command='sleep 5')
opr_respond = PythonOperator(task_id='respond',
python_callable=respond)
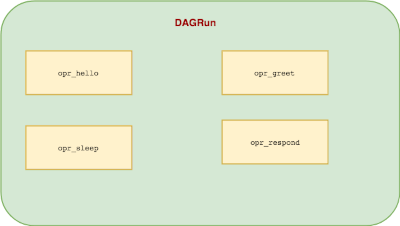
opr_hello >> opr_greet >> opr_sleep >> opr_respond
Ora usando Context Manager stiamo definendo un DAG con le sue proprietà, il primo parametro è l’ID del dag, nel nostro caso è my_simple_dag, il secondo parametro lo abbiamo già descritto, il 3° parametro è qualcosa che deve essere discusso insieme a start_date, che abbiamo menzionato in default_args.
All’interno di quel Context Manager, stiamo assegnando operatori associati all’ID del task. Nel nostro caso questi operatori etichettati come: opr_hello opr_greet opr_sleep e opr_respond. Questi nomi vengono quindi visualizzati nelle caselle rettangolari discusse in precedenza.
Prima di andare oltre, è meglio discutere i DAG Runs e lo Scheduler e quale ruolo svolgono nell’intero flusso di lavoro.
Che cos’è l’utilità di pianificazione di Airflow?
Airflow Scheduler è un processo di monitoraggio che viene eseguito continuamente e attiva l’esecuzione delle attività in base a schedule_interval e execution_date.
Cos’è il DagRun?
Un DagRun è l’istanza di un DAG che verrà eseguito di volta in volta. Quando viene eseguito, verranno eseguite tutte le attività al suo interno.
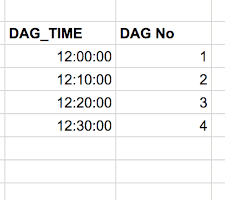
Supponiamo che start_date sia il 3 dicembre 2020 alle 12:00:00 UTC e che il DAG sia stato avviato alle 12:30:00 UTC con il schedule_interval di */10 * * * * (ogni 10 minuti).
Utilizzando gli stessi parametri default_args discusse sopra, di seguito sono riportate le istanze del DAG che verranno eseguite immediatamente, una alla volta dato che nostro caso concurrency è pari 1:
Perché accade questo? Siamo stati noi a deciderlo tramite i parametri di configurazione. Airflow ti offre la possibilità di eseguire i DAG passati. Il processo di esecuzione dei DAG passati si chiama Backfill. Il processo di backfilling consente effettivamente a Airflow di anticipare lo stato di tutti i DAG sin dal suo inizio. La funzione è stata fornita per scenari in cui si esegue un DAG che interroga alcuni DB o API come Google Analytics per recuperare dati precedenti e renderli parte del flusso di lavoro. Anche se non ci sono dati passati, Airflow lo eseguirà comunque per mantenere intatto lo stato dell’intero flusso di lavoro.
Una volta eseguiti i DAG precedenti, il successivo (quello che si intende eseguire) verrà eseguito alle 12:40:00 UTC. DA sottolineare che qualunque sia lo scheduler impostato, il DAG viene eseguito dopo che quell’intervallo di tempo. Nel nostro caso, se deve essere eseguito ogni 10 minuti, verrà eseguito dopo che sono trascorsi 10 minuti.
Esempio di Scheduler
Proviamo. Abilitiamo l’esecuzione di my_simple_dag e avviamo lo scheduler.

Non appena si esegue il DAG si visualizza una schermata simile alla seguente:

my_simple_dag, vediamo una schermata come la seguente: 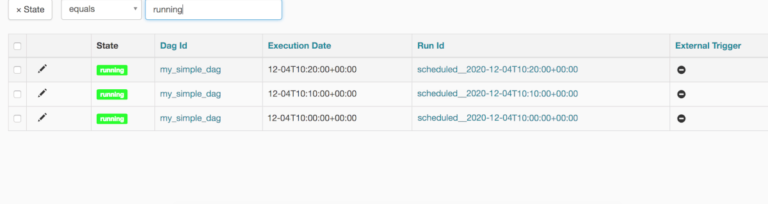
Da notare il timestamp nella colonna Run Id . Vediamo lo schema: Il primo è stato eseguito alle 10:00, poi alle 10:10, alle 10:20. Quindi si interrompe, vorrei chiarire ancora una volta che il DAG viene eseguito una volta trascorso il tempo di durata di 10 minuti. Lo scheduler è iniziato alle 10:30. quindi ha effettuato il backfilling di 3 runs ad intervalli di 10 minuti.
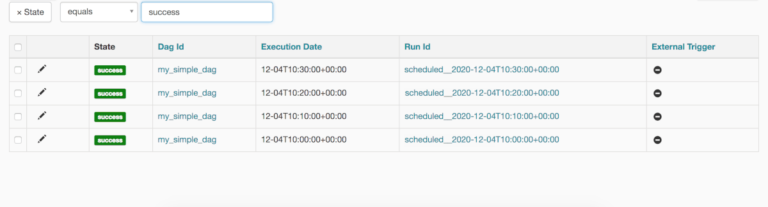
Il DAG che è stato eseguito per le 10:30:00 UTC è stato effettivamente eseguito alle 10:40:00 UTC. L’ultimo record del DAGRun sarà sempre uno meno rispetto all’ora corrente. Nel nostro caso, l’ora della macchina era 10:40:00 UTC
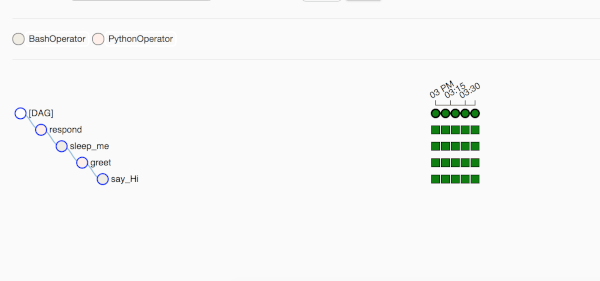
Se passiamo con il mouse su uno dei cerchi si può vedere il timestamp davanti a Run: questo indica l’ora in cui è stato eseguito. Si può notare che questi cerchi verdi hanno un intervallo di tempo di 10 minuti. La Tree View è un po’ complicata ma offre un quadro completo dell’intero flusso di lavoro. Nel nostro caso, è stato eseguito 4 volte e tutte le attività sono state eseguite correttamente, il colore verde scuro.
È possibile evitare il Backfilling in due modi: è possibile impostare start_date con una data futura o impostare catchup = False nell’istanza di DAG. Ad esempio:
with DAG('my_simple_dag',
catchup=False,
default_args=default_args,
schedule_interval='*/10 * * * *',
# schedule_interval=None,
) as dag:
catchup=False non importa se start_date appartiene o meno al passato. Verrà eseguito dall’ora corrente e continuerà. Impostando end_date è possibile interrompere l’esecuzione di un DAG.
opr_hello >> opr_greet >> opr_sleep >> opr_respond
La riga di codice precedente indica la relazione tra gli operatori, quindi costruisce l’intero flusso di lavoro. In questo caso, L’operatore bit a bit sta indicando la relazione tra gli operatori. Quindi opr_hello viene eseguito per primo e poi tutto il resto. Il flusso viene eseguito da sinistra a destra. In forma grafica appare come segue:
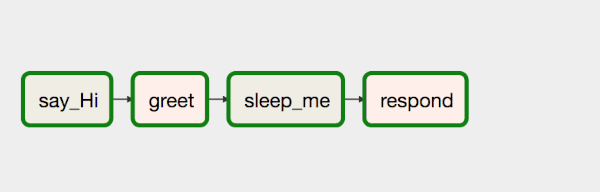
Se modifichiamo la direzione dell’ultimo operatore, come segue:
opr_hello >> opr_greet >> opr_sleep << opr_respond
Iil flusso sarà simile al seguente:
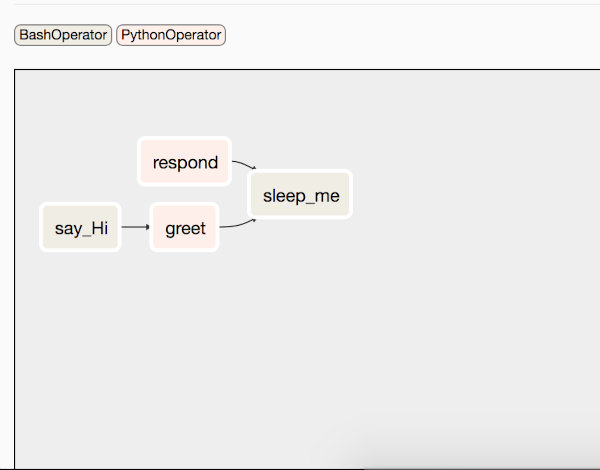
Il taks respond verrà eseguito in parallelo e sleep verrà eseguito in entrambi i casi.
Conclusione
In questo post, abbiamo discusso di come è possibile introdurre un sistema di flusso di lavoro completo per pianificare e automatizzare i flussi di lavoro. Nella parte 2, presenteremo un caso reale per mostrare come è possibile utilizzare Airflow. Volevo includerlo in questo post, ma è già diventato abbastanza lungo ed era necessario spiegare il concetto DAGRun perché mi ci è voluto un po’ di tempo per capirlo.
Come sempre il codice di questo post è disponibile su Github .

No comment yet, add your voice below!