
In questa è la 3°parte del tutorial relativo alla creazione di uno strumento di web scraping con Python, descriviamo come integrare il web scraper schedulato all’interno di un’applicazione web Django.
La 1° parte, Creazione di uno scraper di feed RSS con Python, illustra come utilizzare Requests e Beautiful Soup.
La 2° parte, Web scraping automatizzato con Python e Celery, descrive come pianificare le attività di scraping web con Celery, una coda di task.
Il codice di questo articolo è disponibile pubblicamente su GitHub.
Requisiti
In precedenza, abbiamo creato un semplice lettore di feed RSS che raccoglie informazioni da HackerNews utilizzando Requests e BeautifulSoup. Dopo aver creato lo script di scraping di base, abbiamo descritto come integrare Celery nell’applicazione per fungere da sistema di gestione delle attività. Usando Celery, siamo stati in grado di pianificare le attività di scraping in modo che siano effettuati periodicamente ad intervalli fissi: questo permette di eseguire lo script senza interazione umana.
Il prossimo passo è raggruppare le attività di scraping pianificate in un’applicazione Web utilizzando Django. In questo modo possiamo accedere a un database, visualizzare i dati su un sito Web e terminare la creazione di un’app di “scraping”. L’obiettivo di questo progetto è creare qualcosa di scalabile, simile a un aggregatore.
Questo articolo non è una guida dettagliata al web framework Django. E’ invece orientato verso un approccio “Hello World”, seguito dalla visualizzazione di contenuti acquisiti dall’app web.
Per raggiunge questo obiettivo dobbiamo utilizzare i seguenti strumenti:
- Python 3.7+
- Requests – per le richieste web
- BeautifulSoup 4 – Strumento per il parsing HTML
- Un editor di testo (PyCharm o Visual Studio Code)
- Celery – Coda asincrona di attività con messaggi distribuiti
- RabbitMQ – Un broker di messaggi
- lxml – Se si usa un ambiente virtuale
- Django – Un framework web con Python
- Pipenv – Un pacchetto per gestire ambienti virtuali
Nota: tutte le dipendenze dell’applicazione sono elencate nel file Pipfile/ Pipfile.lock.
Obiettivi
Si vuole realizzare un’applicazione Web che utilizza un sistema di gestione dei task per raccogliere i dati e memorizzarli nel database.
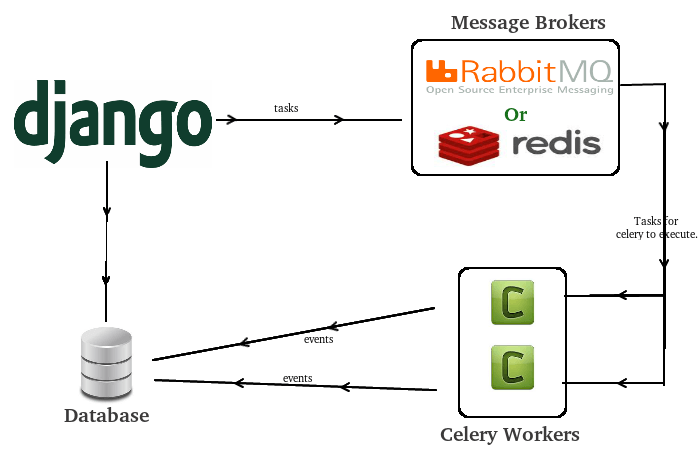
- Installare Django, il framework Python usato per creare la base dell’applicazione web
- Creare un progetto Django e avviare il server
- Generare l’app
scrapingper acqusisire i dati - Configurare
celery.pyetasks.pyper effettuare l’estrazione dei dati - Integrare i dati con la view
HomePagedi Django
Inizializzazione
Per iniziare dobbiamo creare un ambiente virtuale per il progetto Django, e quindi creare lo starter. Questo codice è disponibile su GitHub di Scienzadeidati.com.
Il file Piplock specifca tutti i requisiti del progetto, in questo modo l’ambiente virtuale verrà avviato con tutti i pacchetti necessari.
$ mkdir django_celery_web_scraping && cd django_celery_web_scraping
$ pipenv install requests bs4 lxml django celery
Inoltre, è necessario assicurarsi che RabbitMQ sia installato, come descritto nel precedente articolo.
Nota: in questo articolo stiamo usando Ubuntu, quindi i comandi potrebbero differire a seconda del sistema operativo. Inoltre, per brevità, abbiamo omesso il codice che non ha subito modifiche, usando ….
Creare un progetto Django e avviare il server
Il primo passo per la configurazione del progetto, dobbiamo creare un’istanza di una shell pipenv, e quindi creere un progetto Django. Successivamente, dobbiamo iniziare la creazione dell’applicazione Django ed effettuare le generiche impostazioni.
# django_web_scraping
$ pipenv shell
$ django-admin startproject django_web_scraping .
$ python manage.py createsuperuser
$ python manage.py makemigrations
$ python manage.py migrate
Tramite alcuni dei comandi precedenti, creiamo un’istanza della shell dell’ambiente virtuale per eseguire i comandi Django. Il comando startproject crea l’applicazione iniziale all’interno della directory che stiamo utilizzando . e quindi si eseguono gli altri comandi: createsuperuser, makemigrations, migrate.
E’ ora possibile avviare il server per mostrare che siamo operativi.
Nota: assicuriamoci che questi comandi siano eseguiti in una shell <code>pipenv</code>.
$ python manage.py runserver
localhost:8000 possiamo vedere che il server è avviato e funzionante. 
urls.py dove specificare la view della homepage.
# urls.py
from django.contrib import admin
from django.urls import path, include
from .views import HomePageView # new
urlpatterns = [
path('', HomePageView.as_view(), name='home'), # homepage
path('admin/', admin.site.urls),
]
Quanto sopra è una vista generica importata dal file <code>views.py</code> che dobbiamo creare nella directory principale del progetto
# django_web_scraping/views.py
from django.shortcuts import render
from django.views import generic
# Create your views here.
class HomePageView(generic.ListView):
template_name = 'home.html'
$ mkdir templates && touch templates/base.html && touch templates/home.html
templates alle impostazioni di Django:
# settings.py
TEMPLATES = [
...
'DIRS': ['templates'], # new
...
]
# base.html
{% load static %}
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>{% block title %}Django Web Scraping Example
{% endblock title %}</title>
</head>
<body>
<div class="container">
{% block content %}
{% endblock content %}
</div>
</body>
</html>
{% block %} del modello base.html.
# home.html
{% extends 'base.html' %}
{% block content %}
Hello World
{% endblock content %}
Genera l'app scraping per raccogliere i dati
settings.py e i suoi dati sono passati all’applicazione principale HomePageView.
$ python manage.py startapp scraping
# settings.py
INSTALLED_APPS [
...
'scraping.apps.ScrapingConfig', # new
]
# models.py
from django.db import models
# Create your models here.
class News(models.Model):
title = models.CharField(max_length=200)
link = models.CharField(max_length=2083, default="", unique=True)
published = models.DateTimeField()
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
source = models.CharField(max_length=30, default="", blank=True, null=True)
I campi del modello News hanno i seguenti significati:
title– Dati RSS strutturatilink– Il link dell’articolopublished– La data in cui l’articolo è stato pubblicato su HackerNewscreated_at– La data di immissione dei dati, “now” per impostazione predefinitaupdated_at– La data dell’ultimo aggiornamento dei datisource– HackerNews (o qualsiasi altro sito che scegliamo di analizzare)
Dopo aver creato il modello, l’applicazione Django non viene caricata perché mancano le migrazioni (ovvero la creazione delle tabelle).
$ python manage.py makemigrations
$ python manage.py migrate
Nota: non prevediamo nessun URL per questa app, poiché stiamo solo inviando i dati all’applicazione principale.
Configurazione del file celery.py
I passaggi precedenti in questo articolo hanno descritto le basi per costruire il progetto, vediamo ora come integrare Celery e gli stessi tasks
Questa sezione si basa sul codice descritto negli articoli precedenti. Iniziamo con un file celery.py per l’applicazione Celery, quindi aggiungiamo i task dal codice base dell’articolo Web scraping automatizzato con Python e Celery
$ touch django_web_scraping/celery.py
La configurazione di cui sopra deve essere posizionata all’interno della directory principale del progetto e fungerà da file di “impostazioni” per la coda dei task.
# celery.py
import os
from celery import Celery
from celery.schedules import crontab # scheduler
# default django settings
os.environ.setdefault('DJANGO_SETTINGS_MODULE','django_web_scraping.settings')
app = Celery('django_web_scraping')
app.conf.timezone = 'UTC'
app.config_from_object("django.conf:settings", namespace="CELERY")
app.autodiscover_tasks()
Queste sono le impostazioni predefinite dalla documentazione di Celery, e prevedono che l’applicazione Celery utilizzi il modulo settings ed individuare automaticamente i task.
La seconda configurazione fondamentale prima di creare i task è specificare il file settings.py per il broker di messaggi (RabbitMQ) e Celery.
# settings.py
# celery
CELERY_BROKER_URL = 'amqp://localhost:5672'
CELERY_RESULT_BACKEND = 'amqp://localhost:5672'
CELERY_ACCEPT_CONTENT = ['application/json']
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TIMEZONE = 'UTC'
Includere task.py
I task definiti in tasks.py sono simili a quelli descritti nel precedente articolo. Le principali modifiche sono:
- La funzione di salvataggio
- Come richiamiamo gli oggetti
Anziché salvare i dati dello scraping nei file .txt, prevediamo di memorizzarli come voci nel database predefinito (SQLite).
Iniziamo con la funzione di scraping, per descrivere come i dati sono estratti. Il seguente blocco di codice mostra l’intero task condiviso, con importazioni specifiche per questo task.
# scraping/tasks.py
# scraping
import requests
from bs4 import BeautifulSoup
import json
from datetime import datetime
import lxml
# scraping function
@shared_task
def hackernews_rss():
article_list = []
try:
print('Starting the scraping tool')
# execute my request, parse the data using XML
# parser in BS4
r = requests.get('https://news.ycombinator.com/rss')
soup = BeautifulSoup(r.content, features='xml')
# select only the "items" I want from the data
articles = soup.findAll('item')
# for each "item" I want, parse it into a list
for a in articles:
title = a.find('title').text
link = a.find('link').text
published_wrong = a.find('pubDate').text
published = datetime.strptime(published_wrong, '%a, %d %b %Y %H:%M:%S %z')
# print(published, published_wrong) # checking correct date format
# create an "article" object with the data
# from each "item"
article = {
'title': title,
'link': link,
'published': published,
'source': 'HackerNews RSS'
}
# append my "article_list" with each "article" object
article_list.append(article)
print('Finished scraping the articles')
# after the loop, dump my saved objects into a .txt file
return save_function(article_list)
except Exception as e:
print('The scraping job failed. See exception:')
print(e)
- Inviare una richiesta al feed RSS di HackerNews, ottenere gli elementi elencati, e quindi restituire i dati XML.
- Separare i dati XML in “elementi” utilizzando
soup.findAll('item'), e quindi analizzare i dati utilizzando la libreriaLXML. - Pulire i dati in formato JSON, prestando particolare attenzione al formato della data estratta da
itemper ogni articolo. Questo è importante per salvare gli articoli nel database. - Assicurarsi che le date siano in un formato accettato dal database.
- Aggiungere l’articolo a un elenco di elementi.
- Chiamare la
save_function()con l’elenco di articoli come parametro.
Exception.
Successivamente, iniziamo a esaminare il metodo save_function() che è stato implementato nell’articolo precedente. Questo è stato adattato per utilizzare il modello News che è stato creato all’interno dell’applicazione di scraping.
# scraping/tasks.py
@shared_task(serializer='json')
def save_function(article_list):
print('starting')
new_count = 0
for article in article_list:
try:
News.objects.create(
title = article['title'],
link = article['link'],
published = article['published'],
source = article['source']
)
new_count += 1
except Exception as e:
print('failed at latest_article is none')
print(e)
break
return print('finished')
save_function() utilizza il parametro article_list passato dalla funzione di scraping, e salva ogni oggetto article nel database. Nel repository Github abbiamo previsto una versione aggiornata della funzione save_function() che recupera il più recente articolo di HackerNews salvato nel database ed interrompe l’elaborazione. Invio dei dati alla HomePageView
celery.py e tasks.py, siamo in grado di integrare i dati in HomePageView per mostrarli sull’applicazione web.
Per iniziare, apriamo views.py presente nella root del progetto, quindi aggiungiamo il modello News al suo interno. Questo consente di chiamare gli oggetti tag article all’interno dei modelli Django.
# django_web_scraping/views.py
from scraping.models import News # bring News into the views
class HomePageView(generic.ListView):
template_name = 'home.html'
context_object_name = 'articles'
# assign "News" object list to the object "articles"
# pass news objects as queryset for listview
def get_queryset(self):
return News.objects.all()
Avvio e test dell'applicazione
Dopo avere aggiornato la HomePageView, il progetto è pronto per essere lanciato e testato. In modo analogo alla Parte 1 e alla Parte 2 di questa serie, dobbiamo usare più finestre di terminale.
Per avviare il progetto abbiamo bisogno di:
- Avviare il servizio broker RabbitMQ.
- Avviare il server Django.
- Abilitare i task di Celery.
I passaggi precedenti richiedono più terminali, come descritto di seguito.
Terminale #1 – RabbitMQ
Innanzitutto, verifichiamo che non ci sia in esecuzione un’istanza di RabbitMQ.
Nota: utilizziamo sudo perché l’installazione predefinita non ha concesso le autorizzazioni appropriate.
$ sudo rabbitmqctl shutdown
$ sudo rabbitmq-server start # start server
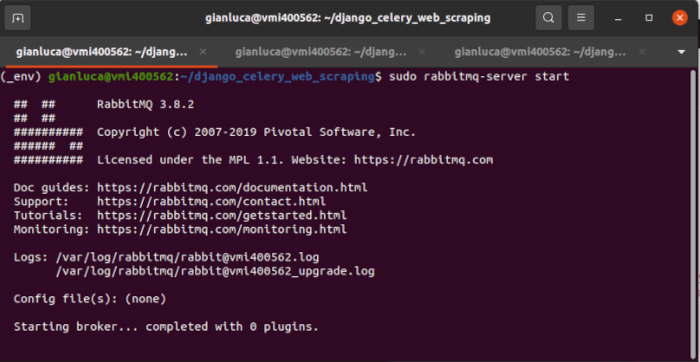
Terminale #2 – Django
Django è facile da avviare, iniziamo solo con il comandorunserver. Usando Pipenv, eseguiamo il comando nella shell
$ pipenv shell
$ python manage.py runserver
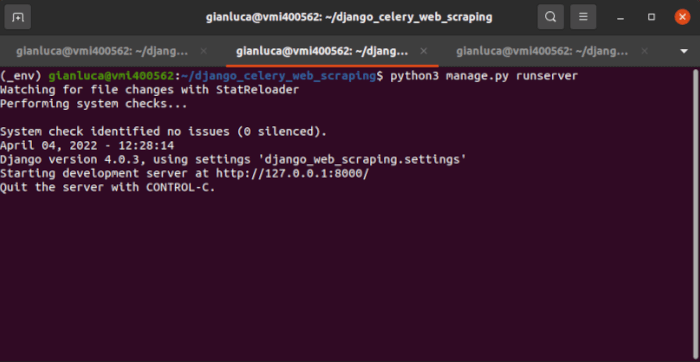
Terminale #3 – Celery
Ora che il progetto è in esecuzione,, possiamo abilitare i task di Celery
$ celery -A django_web_scraping worker -B -l INFO
Una volta che i servizi di cui sopra sono stati avviati, siamo in grado di controllare l’output dello scraping sulla homepage (raggiungibile all’indirizzo 127.0.0.1:8000).
Nella homepage sono visualizzati, in forma tabellare, i dati acquisiti dallo scraping e restituiti dai task di Celery che abbiamo creato. Se osserviamo l’output dei task, vediamo che stanno fallendo perché i dati non soddisfano il vincolo univoco (ad esempio, è un duplicato e non ci sono nuovi post).
Una modifica futura può essere prevedere l’esecuzione di tasks.py a intervalli maggiori, perché il feed RSS probabilmente non avrà molti aggiornamenti ad intervalli di un minuto.
Conclusione
Abbiamo integrato con successo Django, Celery, RabbitMQ e le librerie di web scraping di Python per creare un lettore di feed RSS. Questo tutorial ha fornito una panoramica sull’aggregazione dei dati nella forma di applicazione web, simile a popolari siti (come Feedly).
Possibili sviluppi futuri
- Aggregare altri siti Web o feed di notizie
- Modificare
save_function()in modo da evitare di salvare ogni singolo oggetto ad ogni scraping (meno chiamate al database!!). - Creare un proprio feed RSS, con i dati aggregati.


![scienzadeidati articoli - Database con FASTAPI [Parte2]](https://scienzadeidati.com/storage/scienzadeidati-articoli-Database-con-FASTAPI-Parte2-300x150.jpg)
No comment yet, add your voice below!