
Questa è la 2° parte del tutorial che descrive come creare uno strumento di web scraping con Python. In questo articolo vediamo come integrare Celery, un sistema di gestione delle attività, nel nostro progetto di scraping web.
La 1° parte, Creazione di uno scraper di feed RSS con Python, descrive come utilizzare Requests e Beautiful Soup.
La 3° parte di questa serie, Realizzazione di un’applicazione di web scraping con Python, Celery e Django, descrive come integrare uno strumento di web scraping nelle applicazioni web.
Requisiti
Nell’articolo precedente, abbiamo creato un semplice lettore di feed RSS che estrae informazioni da HackerNews utilizzando Requests e BeautifulSoup (vedi il codice su GitHub).
In questo articolo usiamo il codice come base per la creazione di un sistema di gestione delle attività e lo scraping pianificato.
Il successivo passaggio nella raccolta di dati da siti Web che cambiano frequentemente (ad esempio, un feed RSS che mostra un numero X di elementi alla volta), è quello di eseguire lo scraping su base regolare. Nell’esempio di scraping precedente, abbiamo utilizzato la riga di comando per eseguire il nostro codice; tuttavia, questa non è una soluzione scalabile. Per automatizzare l’esecuzione si può usare Celery per creare un sistema di pianificazione delle attività con esecuzione periodica.
Per raggiunge questo obiettivo dobbiamo utilizzare i seguenti strumenti:
- Python 3.7+
- Requests
- BeautifulSoup4
- Un editor di testo (PyCharm o Visual Studio Code )
- Celery – Coda asincrona di attività con messaggi distribuiti
- RabbitMQ – Broker di messaggi
Nota: tutte le dipendenze della libreria sono elencate nei file requirements.txt e Pipfile/ Pipfile.lock.
Come funziona Celery
Celery è un sistema di gestione delle attività, opera in combinazione con un broker di messaggi per svolgere un lavoro asincrono .
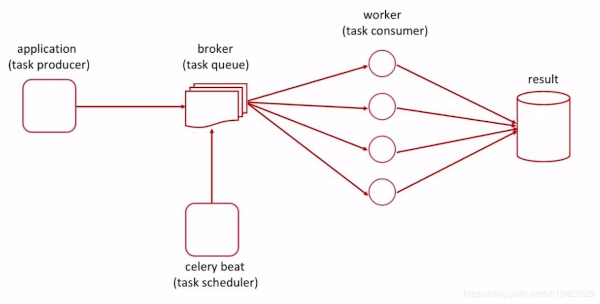
Quanto sopra illustra che il nostro produttore di attività (la nostra app di scraping web) passerà le informazioni sulle attività alla coda (Celery) per essere eseguite. Lo scheduler (Celery beat) li eseguirà come cron job, senza alcun lavoro aggiuntivo o interazione al di fuori dell’avvio dell’app Celery.
Obiettivi
Di seguito uno schema dei passaggi da prevedere per creare la nostra applicazione di scraping automatizzato:
- Installazione di Celery e RabbitMQ: Celery gestisce l’accodamento e l’esecuzione delle attività, mentre RabbitMQ gestirà i messaggi avanti e indietro
- Come avviare RabbitMQ e comprendere i log
- Creazione di un proof-of-concept “Hello World” con Celery per verificarne il funzionamento.
- Registrazione delle funzioni di scraping in tasks.py con Celery
- Sviluppare e gestire ulteriormente le attività di scraping
- Creazione ed esecuzione di una pianificazione per l’attività di scraping
Nota: le introduzioni a RabbitMQ e Celery sono piuttosto lunghe, se si ha già esperienza con questi strumenti si può saltare direttamente al punto 4 .
Inizializzazione
Iniziamo aprendo la directory del progetto, in questo caso è Web_Scraping_RSS_Celery_Django dell’articolo precedente. Se lo desideri, può essere clonato da GitHub tramite il link precedentemente menzionato.
Nota: stiamo usando Ubuntu, quindi i comandi potrebbero differire a seconda del sistema operativo.
Inoltre, per brevità, abbiamo omesso parti di codice replicato, usando ….
Infine, i requisiti del progetto possono essere installati utilizzando il comando pip come nel seguente esempio.
$ pip install celery
Perché Celery e RabbitMQ? Perché non un'altra tecnologia?
Utilizziamo Celery e RabbitMQ perché sono abbastanza semplici da configurare, testare e ridimensionare in un ambiente di produzione. Sebbene possiamo eseguire un’attività periodica utilizzando altre librerie, o semplicemente con i cron job generali, vogliamo costruire qualcosa da riutilizzare nei prossimi progetti.
Una soluzione sarà più duratura e richiede meno manutenzione se usiamo una tecnologia che possiamo scalare nel prossimo progetto, imparando alcuni comandi e strumenti chiave man mano che aumentiamo gradualmente la complessità.
Configurazione di RabbitMQ
Far funzionare un server RabbitMQ è molto più semplice su Ubuntu rispetto a un ambiente Windows. Seguiremo la documentazione ufficiale della guida all’installazione.
Ecco i comandi di installazione per Debian e Ubuntu:
$ sudo apt-get update -y
$ sudo apt-get install curl gnupg -y
$ curl -fsSl https://github.com/rabbitmq/signing-keys/releases/download/2.0/rabbitmq-release-signing-key.asc | sudo apt-key add -
$ sudo apt-get install apt-transport https
$ sudo tee /etc/apt/sources.list.d/bintray.rabbitmq.list <<EOF
$ deb https://dl.bintray.com/rabbitmq-erlang/debian bionic erlang
$ deb https://dl.bintray.com/rabbitmq/debian bionic main
$ EOF
$ sudo apt-get update -y
$ sudo apt-get install rabbitmq-server -y --fix-missing
Dopo aver installato RabbitMQ per la prima volta in un ambiente virtuale, si avvia automaticamente. Per verificare che il comando rabbitmq-server funzioni (quello da usare con Celery), è necessario disattivare il servizio.
Da notare che le autorizzazioni predefinite per l’installazione prevedono che Only root or rabbitmq should run rabbitmqctl shutdown, che può risultare strano. Per risolverlo, possiamo semplicemente eseguire il comando con sudo.
$ sudo rabbitmqctl shutdown
E’ quindi possibile testare il server utilizzando il comando rabbitmq-server,
$ sudo rabbitmq-server
Si ottiene il seguente output
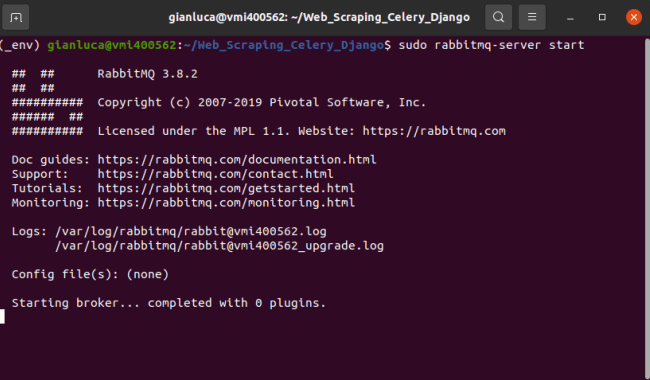
NOTA: si può terminare il comando rabbitmq-server usando Control+C.
La configurazione di RabbitMQ su Windows richiede passaggi aggiuntivi. La documentazione ufficiale contiene una guida per l’installazione manuale.
Testare Celery con RabbitMQ
Prima di immergersi nella codifica di ogni progetto, è buona norma testare gli esempi di base in stile “Hello World” per i pacchetti e framework previsti dal progetto. Questo permette di acquisire una comprensione di base di cosa è possibile aspettarsi, insieme ad alcuni comandi del terminale da aggiungere alla cassetta degli attrezzi per quella specifica tecnologia.
In questo caso, Celery viene fornito con il proprio proof-of-concept “Hello World” sotto forma di un’attività (task) che effettua una semplice addizione aritmetica. Questo è disponibile in forma estesa sulla documentazione ufficiale di Celery. Di seguito viene descritto brevemente; tuttavia, se si desidera spiegazioni o approfondimenti, è consigliato leggere la documentazione ufficiale.
Ora che abbiamo installato e convalidato il broker RabbitMQ, possiamo iniziare a creare il file tasks.py. Questo contiene tutte le attività (task) da eseguire, sia che si tratti di una operazione aritmetica, di uno scraping web o di un salvataggio di utenti in un database. Vediamo ora le modifiche all’interno della directory del progetto.
$ touch tasks.py
Per creare un task per effettuare un’addizione aritmetica, dobbiamo importare la libreria Celery e creare una funzione con il flag @app.task per consentire ai worker di Celery di ricevere l’attività nel sistema di code.
# tasks.py
from celery import Celery
app = Celery('tasks') # defining the app name to be used in our flag
@app.task # registering the task to the app
def add(x, y):
return x + y
Utilizzando il task add, possiamo iniziare a testarne l’esecuzione. È qui che le cose potrebbero iniziare a confondersi, poiché nel passaggio successivo sono necessari 3 terminali aperti contemporaneamente.
Iniziamo con una rapida spiegazione, quindi descriviamo il codice e visualizzare le schermate.
Spiegazione
Per completare il test, eseguiamo il task Celery usando la riga di comando importando il tasks.py e poi lanciarlo. Affinché i task siano ricevuti dalla coda, dobbiamo avere attivi i servizi Celery worker e RabbitMQ. Il server RabbitMQ funge da nostro broker di messaggi mentre il worker Celery esegue le attività.
Indichiamo ogni passaggio con i numeri di terminale:
- Rabbit MQ
- Worker di Celery
- Esecuzione del task
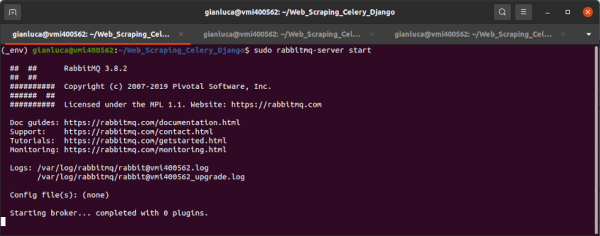
Terminale #1
Iniziamo avviando il server RabbitMQ nel terminale n. 1.
# RabbitMQ
$ sudo rabbitmq-server
Terminale #2
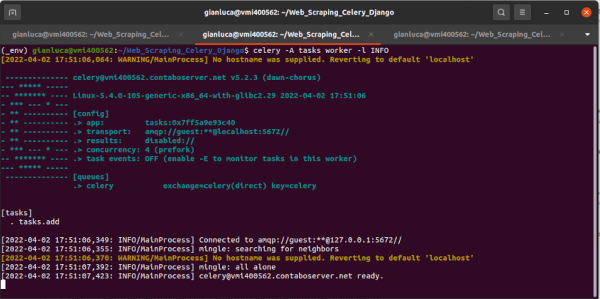
Successivamente, possiamo avviare il processo del worker Celery nel terminale n. 2. Descriviamo anche le impostazioni dettagliate per il worker in modo da illustrare come apparirà l’output.
Nota: deve essere eseguito dalla directory del progetto.
# Celery worker
$ celery -A tasks worker -l INFO
Analizziamo il precedente comando:
celery– La libreriache stiamo chiamando-A tasks– Si esplicita che vogliamo l’apptasksworker– Avvio del processo worker-l INFO– Garantisce di avere un dettagliato log degli eventi nella console
Per verificare se il worker è stato avviato correttamente, è necessario avere la riga concurrency: 4 (prefork) nel terminale.
Inoltre, notiamo che l’app [tasks] è stata importata, insieme alla registrazione dei task presenti in tasks.py. Il worker ha registrato una singola attività (1), tasks.add.
Terminale #3:
Successivamente, possiamo iniziare l’esecuzione del test nel terminale n. 3. Eseguiamo un ciclo per eseguire più task che vengono catturati dal servizio worker. Lo realizziamo importando add da tasks.py, e quindi eseguendo un ciclo for.
Nota: dopo la riga add.delay(i, i), si deve usare Control+Invio per eseguire il comando.
$ python
>>> from tasks import add # pulling in add from tasks.py
>>> for i in range(1000):
... add.delay(i, i) # delay calls the task
Ora possiamo a vedere un grande blocco di output nel terminale n. 3 (l’esecuzione dell’attività Celery).
Questo mostra che il worker sta ricevendo il risultato dell’attività dal terminale n. 2.
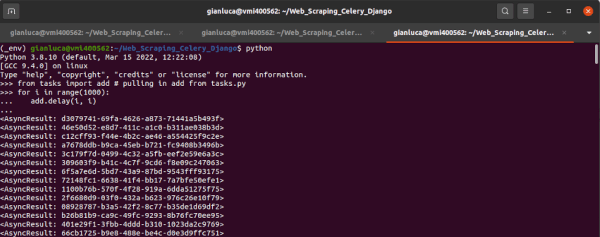
Terminale 2:
Se controlliamo il worker Celery nel terminale n. 2, il processo che esegue l’addizione aritmetica, vediamo che sta rilevando ciascuna delle esecuzioni dell task.
Abbiamo dimostrato con successo che Celery e RabbitMQ sono installati correttamente. Questo getta le basi per gli altri task che vogliamo implementare (es. web scraping) dimostrando come interagiscono Celery, Celery worker e RabbitMQ.
Ora che abbiamo coperto l’installazione e le nozioni di base, ci addentreremo nella tasks.pycreazione delle nostre attività di scraping web.
Creazione del task.py con Celery per il web scraping
L’esempio descritto nel paragrafo precedente ha aiutato a descrivere il processo da usare per eseguire i task utilizzando Celery, dimostrando anche come i task sono registrati tramite i worker di Celery.
Basandoci sul questo esempio, iniziamo creando i task di scraping. A tale scopo, per semplicità possiamo copiare il codice dello script scraping.py, descritto nella 1° parte di questo tutorial, nel file tasks.py.
Quindi possiamo rimuovere la funzione def add(x, y) dell’esempio e copiare l’importazione delle librerie (Requests e BeautifulSoup), e le funzioni di scraping.
Nota: usiamo le stesse funzioni, solamente che sono state copiate in tasks.py.
# tasks.py
from celery import Celery
import requests # pulling data
from bs4 import BeautifulSoup # xml parsing
import json # exporting to files
app = Celery('tasks')
# save function
def save_function(article_list):
with open('articles.txt', 'w' as outfile:
json.dump(article_list, outfile)
# scraping function
def hackernews_rss():
article_list = []
try:
# execute my request, parse the data using the XML
# parser in BS4
r = requests.get('https://news.ycombinator.com/rss')
soup = BeautifulSoup(r.content, features='xml')
# select only the "items" I want from the data
articles = soup.findAll('item')
# for each "item" I want, parse it into a list
for a in articles:
title = a.find('title').text
link = a.find('link').text
published = a.find('pubDate').text
# create an "article" object with the data
# from each "item"
article = {
'title': title,
'link': link,
'published': published
}
# append my "article_list" with each "article" object
article_list.append(article)
# after the loop, dump my saved objects into a .txt file
return save_function(article_list)
except Exception as e:
print('The scraping job failed. See exception: ')
print(e)
Le funzioni di web scraping sono ora in tasks.py, insieme alle loro dipendenze. Il passaggio successivo è registrare i task con la app Celery, semplicemente specificando il decorator @app.task prima di ogni funzione.
# tasks.py
... # same as above
@app.task
def save_function(article_list):
...
@app.task
def hackernews_rss():
...
Miglioramenti alle funzioni di scraping
Sebbene le funzioni di scraping già implementate abbiano dimostrato di funzionare per estrarre i dati dal feed RSS di HackerNews, abbiamo ancora qualche margine di miglioramento. Di seguito abbiamo descritto le modifiche da fare all’interno del set di strumenti di scraping prima di automatizzare l’esecuzione dello script.
- Salvare l’output in file .json con data e ora.
- Aggiungere una data e ora
created_atper ogni articolo. - Aggiungere una stringa
source, nel caso in cui desideriamo fare lo scraping di altri siti
Le precedenti modifiche sono semplici perchè abbiamo già effettuato la maggior parte del lavoro di implementazione durante il primo articolo. Sebbene non sia significativo, lo scambio in .json sarà un po’ più facile da leggere rispetto a .txt. Inoltre i due campi aggiuntivi contengono informazione che rendono l’applicazione più “scalabile” quando si aggiungono altri feed per lo scraping e quando si analizzano i dati in un secondo momento.
Iniziamo con aggiornare la funzione save_function per produrre un file .json e aggiungere un timestamp. In questo modo si migliora la qualità del lavoro quando dobbiamo riutilizzare dati di scraping precedenti.
# tasks.py
from datetime import datetime # for time stamps
...
def save_function(articles_list):
# timestamp and filename
timestamp = datetime.now().strftime('%Y%m%d-%H%M%S')
filename = 'articles-{}.json'.format(timestamp)
# creating our articles file with timestamp
with open(filename, 'w').format(timestamp) as outfile:
json.dump(article_list, outfile)
Stiamo usando la funzione datetime.now().strftime(...) per creare un timestamp da aggiungere al file usando .format(timestamp).
Passando alle due modifiche all’interno della funzione hackernews_rss(), aggiungiamo alcune informazioni sulla fonte (HackerNews RSS) e un timestamp created_at. Si tratta di due semplici modifiche che ci aiutano a differenziare le informazioni nel caso si voglia aggiungere ulteriori funzioni di scraping.
# tasks.py
...
def hackernews_rss():
...
for a in articles:
...
article = {
...
'created_at': str(datetime.now()),
'source': 'HackerNews RSS'
}
...
created_at e source.
Un rapido suggerimento: se ometti amo la transizione str() lo script non verrà eseguito a causa di un errore Object of type datetime is not JSON serializable. Pianificazione dei task con Celery:
Ora sfruttiamo i poteri di pianificazione dei task di Celery utilizzando beat_schedule. Questo ci consente di registrare i task con l’agente di pianificazione in orari specifici.
Un’ottima guida per la schedulazione di task è sicuramente all’interno della documentazione ufficiale . Ci sono anche alcuni esempi di pianificazione aggiuntivi nel file tasks.py del repository GitHub di questo tutorial.
Prevediamo di eseguire il task di scraping ogni minuto, in modo da dimostrere come il worker Celery interagisce con i task pianificati. Ciò non comporterà dati diversi, poiché questo feed RSS non viene aggiornato ogni minuto con nuovi dati.
L’obiettivo di questo esempio è mostrare l’ouput dei file degli articoli e una semplice pianificazione dei task.
Creazione dello scheduler
# tasks.py
...
from celery.schedules import crontab # scheduler
# scheduled task execution
app.conf.beat_schedule = {
# executes every 1 minute
'scraping-task-one-min': {
'task': 'tasks.hackernews_rss',
'schedule': crontab()
}
}
...
La configurazione di cui sopra registra le pianificazioni dei task all’interno della stessa app Celery. All’avvio, siamo in grado di chiamare lo scheduler di Celery per ricontrollare ciò che è stato messo in coda.
Esecuzione dei task
Ora che il codice è stato completato, è ora di accendere il server RabbitMQ e avviare i worker Celery.
Per questo esempio, utilizziamo 2 schede del terminale:
- Server RabbitMQ
- Worker di Celery
Terminale #1
Per avviare il server RabbitMQ (il broker di messaggi), usiamo lo stesso comando descritto in precedenza.
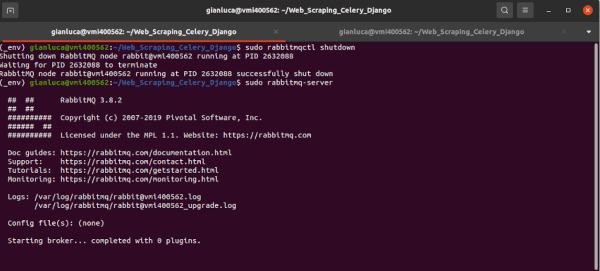
Nota: si può anche prevedere di ricontrollare che il nodo creato all’avvio sia spento, poiché non si avvia con i log e genererà un errore se non viene terminato in precedenza.
$ sudo rabbitmqctl shutdown
$ sudo rabbitmq-server
Si ottiene un output simile a l precedente esempio (come il seguente screenshot).
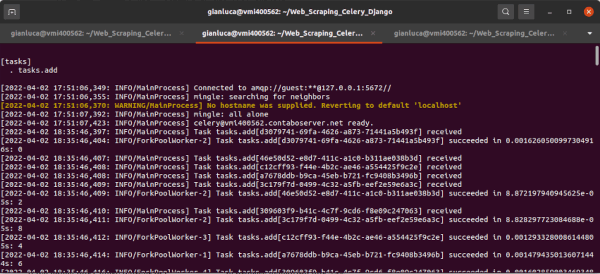
Una volta avviato il server RabbitMQ, possiamo iniziare con il terminale n. 2.
Terminale #2
Modifichiamo leggermente il comando, poiché ora include una notazione per -B la quale chiama il worker che esegue il beat scheduler.
$ celery -A tasks worker -B -l INFO
- Si registra il
[tasks] - Avvio dello scheduler
beat - Il worker
MainProcessriceve un’attivitàReceived task: tasks.hackernews_rss - Avvio di
ForkPoolWorkered esecuzione del task, quindi restituisce un risultato
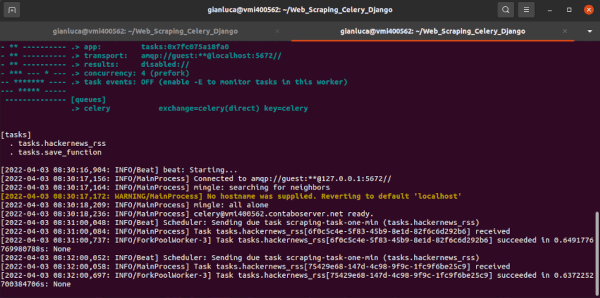
Suggerimento: possiamo interrompere l’esecuzione del task pianificato con Control + C, dato che il task viene eseguito a tempo indeterminato.
Dopo che il task è stato eseguito correttamente, la funzione save_function() ha generato il file .json.
Conclusione
In questo articolo abbiamo ampliato con successo un semplice strumento di web scraping in modo di prevedere una pianificazione dell’esecuzione. Ciò garantisce che non abbiamo più bisogno di eseguire manualmente lo script di scraping e che possiamo “impostarlo e dimenticarlo”. Tramite la schedulazione dello script, l’applicazione sarà in grado di analizzare i siti alla ricerca di dati che cambiano in base a una pianificazione prestabilita (ad esempio, ogni 15 minuti) e restituire ogni volta nuovi dati.
Quali sono i prossimi passi?
Nella parte 3, descriviamo un’applicazione Django con integrazione di Celery e web scraping. Questo è un ottimo esempio di un’applicazione web che effettua lo scraping e popola un sito web con informazioni dello scraping. Il prodotto finale sarà un aggregatore di notizie che estrae da più feed RSS.