![scienzadeidati articoli - Database con FASTAPI [Parte2]](https://scienzadeidati.com/storage/jupiterx/images/scienzadeidati-articoli-Database-con-FASTAPI-Parte2-75a4ee3.jpg)
Introduzione
Lo scopo di questo articolo è creare una semplice guida su come utilizzare FastAPI con database relazionali in modo asincrono e utilizzare Alembic per le migrazioni.
Prima di iniziare con questo tutorial, leggi la parte 1 di questo tutorial.
Ecco il codice funzionante completo su github.
Iniziamo
Installa il pacchetto richiesto databases.
databases è un pacchetto leggero con supporto asyncio per molti database relazionali e utilizza le principali query di sqlalchemy.
Per lo scopo di questo tutorial userò pipenv , ma puoi usare pip o poetry o conda o qualsiasi altro gestore di pacchetti che preferisci.
pipenv install databases
pipenv install databases[postgresql]
pipenv install asyncpg
useremo la stessa configurazione docker descritta nell’articolo precedente.
Dockerfile
# Pull base image
FROM python:3.7
# Set environment varibles
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
WORKDIR /code/
# Install dependencies
RUN pip install pipenv
COPY Pipfile Pipfile.lock /code/
RUN pipenv install --system --dev
COPY . /code/
EXPOSE 8000
docker-compose.yml
version: "3"
services:
db:
image: postgres:11
ports:
- "5432:5432"
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=test_db
web:
build: .
command: bash -c "uvicorn main:app --host 0.0.0.0 --port 8000 --reload"
volumes:
- .:/code
ports:
- "8000:8000"
depends_on:
- db
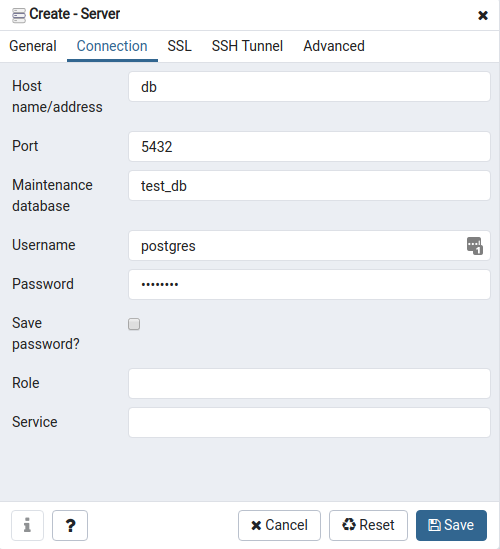
pgadmin:
container_name: pgadmin
image: dpage/pgadmin4
environment:
- [email protected]
- PGADMIN_DEFAULT_PASSWORD=admin
ports:
- "5050:80"
depends_on:
- db
manterremo schema.py così com’è
# schema.py
from pydantic import BaseModel
class User(BaseModel):
first_name: str
last_name: str
age: int
class Config:
orm_mode = True
Analogamente manteniamo lo stesso alembic.ini.
Modifichiamo il file .env come segue:
DATABASE_URL=postgresql://postgres:postgres@db:5432/postgres
ed lo utilizziamo nel file db.py dove inizializzeremo il nostro database.
# db.py
import os
from databases import Database
from dotenv import load_dotenv
import sqlalchemy
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
load_dotenv(os.path.join(BASE_DIR, ".env"))
db = Database(os.environ["DATABASE_URL"])
metadata = sqlalchemy.MetaData()
A questo punto dobbiamo prevedere il file app.py, dove gestiremo l’inizializzazione dell’app con la connessione e la terminazione del database.
# app.py
from db import db
from fastapi import FastAPI
app = FastAPI(title="Async FastAPI")
@app.on_event("startup")
async def startup():
await db.connect()
@app.on_event("shutdown")
async def shutdown():
await db.disconnect()
model.py.
# model.py
from db import db
users = sqlalchemy.Table(
"users",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("first_name", sqlalchemy.String),
sqlalchemy.Column("last_name", sqlalchemy.String),
sqlalchemy.Column("age", sqlalchemy.Integer),
)
model.py, creando una semplice classe di gestione del modello User
# model.py
import sqlalchemy
from db import db, metadata, sqlalchemy
users = sqlalchemy.Table(
"users",
metadata,
sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True),
sqlalchemy.Column("first_name", sqlalchemy.String),
sqlalchemy.Column("last_name", sqlalchemy.String),
sqlalchemy.Column("age", sqlalchemy.Integer),
)
class User:
@classmethod
async def get(cls, id):
query = users.select().where(users.c.id == id)
user = await db.fetch_one(query)
return user
@classmethod
async def create(cls, **user):
query = users.insert().values(**user)
user_id = await db.execute(query)
return user_id
Questa classe fornirà un’implementazione più semplice per i metodi get e create.
Di conseguenza dobbiamo modificare il file main.py come segue.
# main.py
import uvicorn
from models import User as ModelUser
from schema import User as SchemaUser
from app import app
from db import db
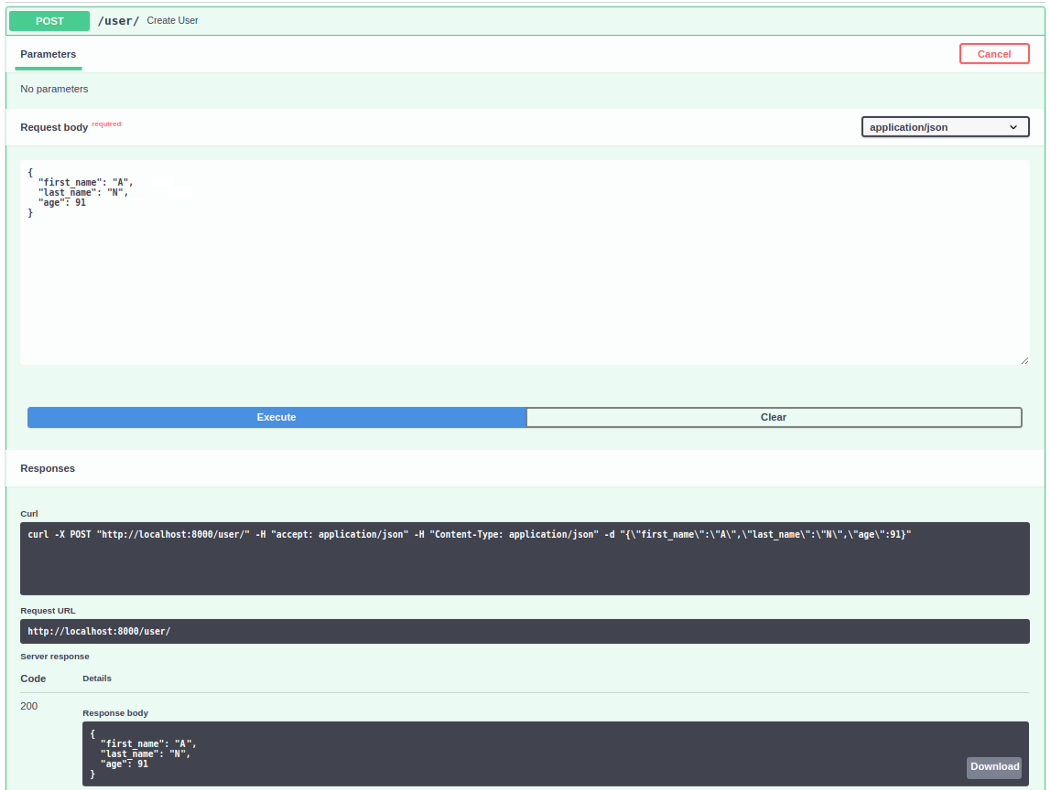
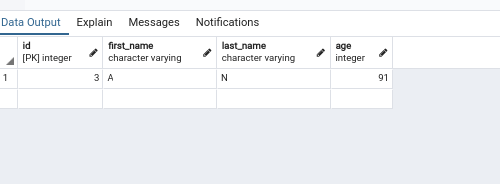
@app.post("/user/")
async def create_user(user: SchemaUser):
user_id = await ModelUser.create(**user.dict())
return {"user_id": user_id}
@app.get("/user/{id}", response_model=SchemaUser)
async def get_user(id: int):
user = await ModelUser.get(id)
return SchemaUser(**user).dict()
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
Da notare come ora stiamo usando async/await per gestire le chiamate verso il database.
È tempo quindi di modificare la configurazione del nostro Alembic.
Bisogna modificareimport models
target_metadata = models.Base.metadata
inimport modelsfrom db import metadata
target_metadata = metadata
NOTA: è importante importare i modelli prima dei metadati.
Quindi procediamo a ricompilare il nostro Docker:
- Costruzione:
docker-compose build - Creazioni migrazioni:
docker-compose run web alembic revision --autogenerate - Migrazione:
docker-compose run web alembic upgrade head - Esecuzione:
docker-compose up
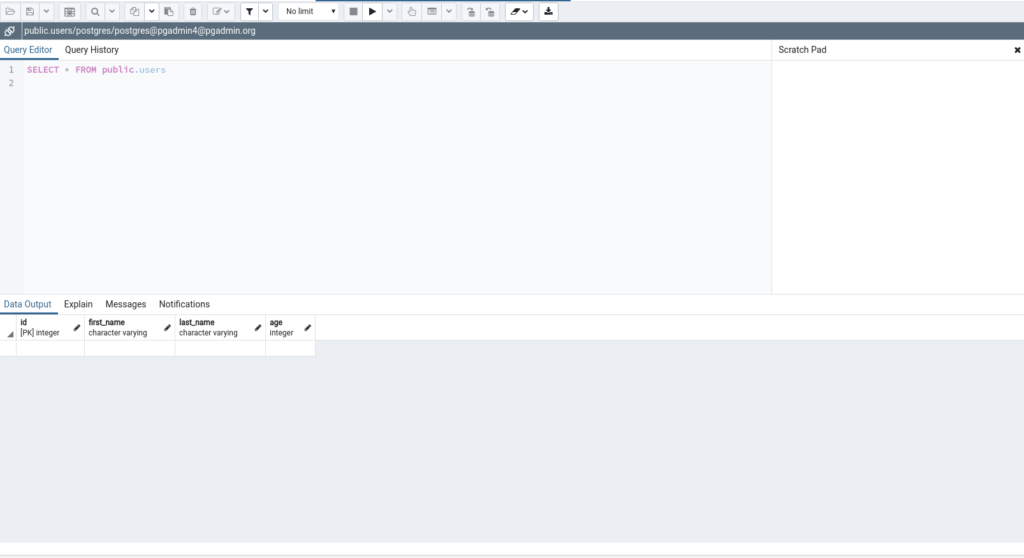
Ora aprendo il browser e collegarsi a http://localhost:8000
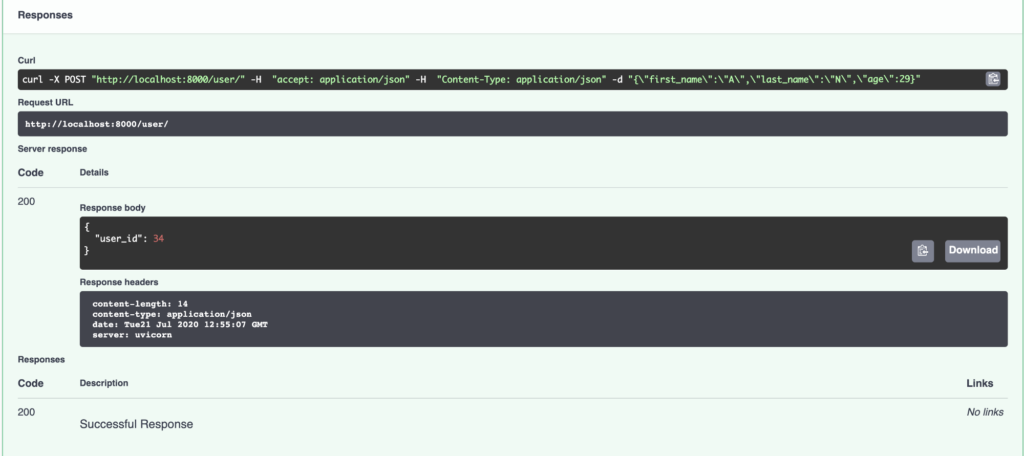
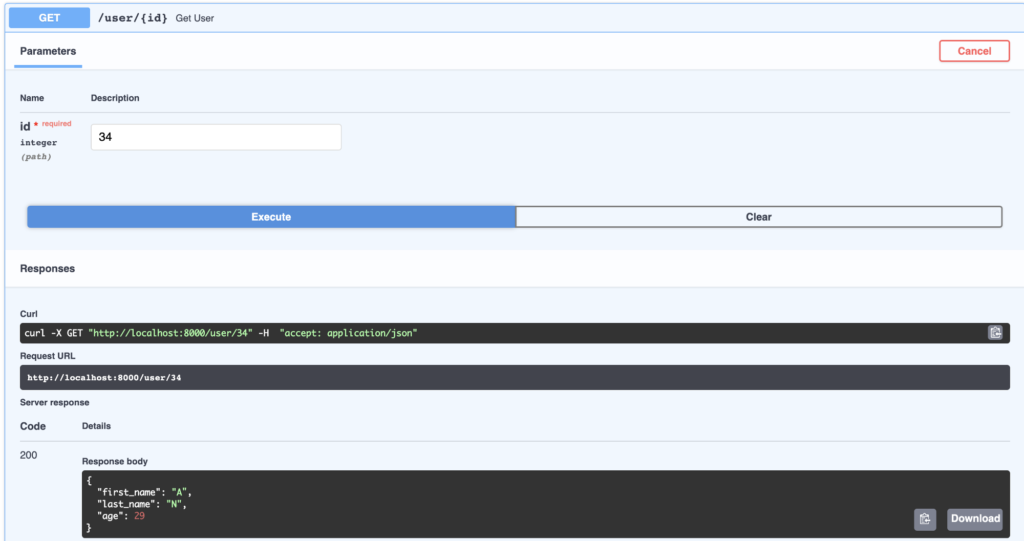
Spero che questo tutorial sia stato abbastanza completo su come utilizzare FastAPI con PostgreSQL, SQLAlchemy e Alembic utilizzando la potenza di async .
Il codice completo per questo articolo è disponibile su github.