
Nel post precedente , abbiamo introdotto Apache Airflow e i suoi concetti di base, la configurazione e l’utilizzo. In questo post, descriviamo come possiamo pianificare i nostri web scraper con l’aiuto di Apache Airflow.
A titolo di esempio, vedremo come effettuare lo scraping del sito https://allrecipes.com tramite perché lo scopo è utilizzare Airflow. Nel caso si desideri approfondire il web scraping si può consultare l’intera serie presente qui su scienzadeidati.com.
Quindi, lavoreremo su un flusso di lavoro composto dalle seguenti attività:
- parse_recipes: analizza le singole ricette.
- download_image: scarica l’immagine della ricetta.
- store_data: memorizza l’immagine e i dati analizzati in un database MySQL
Non descriviamo come pianificare i DAG e altre cose che abbiamo già trattato nella Parte 1.

Abbiamo impostato load_examples=False in airflow.cfg in modo da semplificare l’interfaccia ed avere solo i DAG che ci interessano. La struttura del codice di base è simile alla seguente:
import datetime as dt
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
def parse_recipes():
return 'parse_recipes'
def download_image():
return 'download_image'
def store_data():
return 'store_data'
default_args = {
'owner': 'airflow',
'start_date': dt.datetime(2020, 12, 1, 10, 00, 00),
'concurrency': 1,
'retries': 0
}
with DAG('parsing_recipes',
catchup=False,
default_args=default_args,
schedule_interval='*/10 * * * *',
# schedule_interval=None,
) as dag:
opr_parse_recipes = PythonOperator(task_id='parse_recipes',
python_callable=parse_recipes)
opr_download_image = PythonOperator(task_id='download_image',
python_callable=download_image)
opr_store_data = PythonOperator(task_id='store_data',
python_callable=store_data)
opr_parse_recipes >> opr_download_image >> opr_store_data
Se registriamo questo DAG eseguendo airflow scheduler, otteniamo qualcosa di simile:
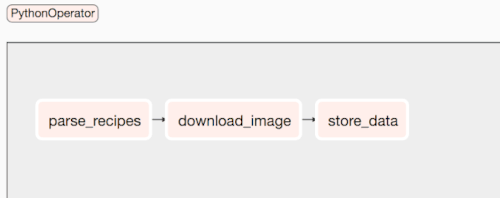
Da notare la potenza dei flussi di lavoro. E’ possibile visualizzare lo scheletro della nostra pipeline in modo da avere un’idea del nostro flusso dati senza entrare nei dettagli. Bello, vero?
Ora, implementiamo una per una le routine di ogni task. Prima di entrare nella logica di parse_recipies, è fondamentale descrivere come i task di Airflow possono comunicare tra loro.
Cos’è XCOM?
XCOM fornisce i metodi per far comunicare i task tra di loro. I dati inviati da un task vengono acquisiti da un’altro task. Se impostiamo provide_context=True, il valore restituito della funzione viene inserito in XCOM che di per sé non è altro che una tabella Db. Se controlliamo airflow.db troveremo una tabella con il nome xcom, al cui interno sono presenti le voci delle istanze di attività in esecuzione.
def parse_recipes(**kwargs):
return 'RETURNS parse_recipes'
Il primo task non prevede ha tali modifiche oltre a fornire **kwargs che consentono di condividere coppie chiave/valore. E’ comunque necessario impostare provide_context=True per ogni operatore, in modo da renderlo compatibile con XCom. Ad esempio:
opr_parse_recipes = PythonOperator(task_id='parse_recipes',
python_callable=parse_recipes, provide_context=True)
Il task download_image avrà le seguenti modifiche:
def download_image(**kwargs):
ti = kwargs['ti']
v1 = ti.xcom_pull(key=None, task_ids='parse_recipes')
print('Printing Task 1 values in Download_image')
print(v1)
return 'download_image'
Con prima riga è ti=kwargs['t1'] otteniamo i dettagli delle istanze tramite la chiave di accesso ti.
Vediamo in dettaglio perchè è necessario prevedere l’uso di queste chiavi di accesso. Se analizziamo il parametro kwargs, otteniamo una stampa simile alla seguente, dove sono presenti chiavi come t1, task_instance, ecc… che contengono il valore inviato da un task:
{
'dag': <DAG: parsing_recipes>,
'ds': '2020-12-02',
'next_ds': '2020-12-02',
'prev_ds': '2020-12-02',
'ds_nodash': '20201202',
'ts': '2020-12-02T09:56:05.289457+00:00',
'ts_nodash': '20201202T095605.289457+0000',
'yesterday_ds': '2020-12-01',
'yesterday_ds_nodash': '20201201',
'tomorrow_ds': '2020-12-03',
'tomorrow_ds_nodash': '20201203',
'END_DATE': '2020-12-02',
'end_date': '2020-12-02',
'dag_run': <DagRunparsing_recipes@2020-12-0209:56:05.289457+00:00:manual__2020-12-02T09:56:05.289457+00:00, externallytriggered: True>,
'run_id': 'manual__2020-12-02T09:56:05.289457+00:00',
'execution_date': <Pendulum[2020-12-02T09: 56: 05.289457+00:00]>,
'prev_execution_date': datetime.datetime(2020,12,2,9,56,tzinfo=<TimezoneInfo[UTC,GMT,+00:00:00,STD]>),
'next_execution_date': datetime.datetime(2020,12,2,9,58,tzinfo=<TimezoneInfo[UTC,GMT,+00:00:00,STD]>),
'latest_date': '2020-12-02',
'macros': <module'airflow.macros'from'/anaconda3/anaconda/lib/python3.6/site-packages/airflow/macros/__init__.py'>,
'params': {},
'tables': None,
'task': <Task(PythonOperator): download_image>,
'task_instance': <TaskInstance: parsing_recipes.download_image2020-12-02T09: 56: 05.289457+00:00[running]>,
'ti': <TaskInstance: parsing_recipes.download_image2020-12-02T09: 56: 05.289457+00:00[running]>,
'task_instance_key_str': 'parsing_recipes__download_image__20201202',
'conf': <module'airflow.configuration'from'/anaconda3/anaconda/lib/python3.6/site-packages/airflow/configuration.py'>,
'test_mode': False,
'var': {
'value': None,
'json': None
},
'inlets': [],
'outlets': [],
'templates_dict': None
}
Nella riga successiva si richiama il metodo xcom_pull per inserire il valore restituito di un determinato task. Nel nostro caso l’ID task è parse_recipes:
v1 = ti.xcom_pull(key=None, task_ids='parse_recipes')
Bene, dopo aver descritto il concetto di XCOM, torniamo al nostro codice originale.
Quindi il nostro processo prevede un primo task che legge gli URL dal file di testo (possiamo anche creare un altra task che sarà responsabile solo di recuperare i collegamenti url e archiviarli in un file o DB. Lascio questa implementazione a voi lettori! ) e quindi la list delle voci viene passata al successivo task che ha il compito di scaricare le immagini e aggiungere le informazioni del file appena scaricato in un dict e infine memorizzarlo nel database MySQL.
Il metodo download_image appare ora come segue:
def download_image(**kwargs):
local_image_file = None
idx = 0
records = []
ti = kwargs['ti']
parsed_records = ti.xcom_pull(key=None, task_ids='parse_recipes')
for rec in parsed_records:
idx += 1
image_url = rec['image_url']
r_url = rec['url']
print('Downloading Pic# {}'.format(idx))
local_image_file = dl_img(image_url, r_url)
rec['local_image'] = local_image_file
records.append(rec)
return records
Non descriviamo il metodo dl_img dato che esula dallo scopo di questo post. Se vuoi puoi controllare il codice direttamente su Github. Una volta scaricato il file, aggiungiamo la chiave nel record originale.
Il metodo store_data appare ora come segue:
def store_data(**kwargs):
ti = kwargs['ti']
parsed_records = ti.xcom_pull(key=None, task_ids='download_image')
print('PRINTING DUMPED RECORDS in STORE DATA')
print(parsed_records)
return 'store_data'
Assicuriamoci di impostare provide_context=True per l’operatore opr_store_data altrimenti si ottiene il seguente errore:
Subtask store_data KeyError: 'ti'
Ora che i dati sono disponibili., sono inviati per essere memorizzati nel database MySQL.
Per utilizzare MySQL con Airflow, utilizzeremo gli hook forniti da Airflow.
Airflow Hooks ci consente di interagire con sistemi esterni: e-mail, S3, database e vari altri.
Prima di iniziare a programmare, dobbiamo configurare una connessione MySQL.
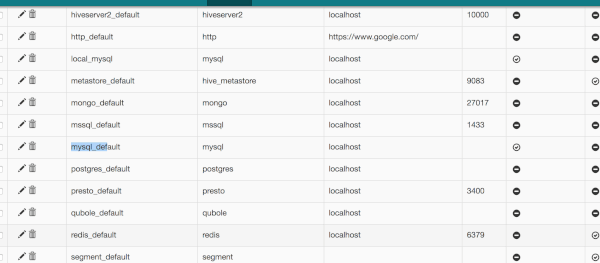
Sull’interfaccia utente Web di Airflow, dobbiamo andare su Amministratore > Connessioni. Qui abbiamo un elenco di connessioni esistenti se ci colleghiamo a http://0.0.0.0:8080/admin/connection/
Modifichiamo la connessione e impostiamo il nome e la password della tabella.
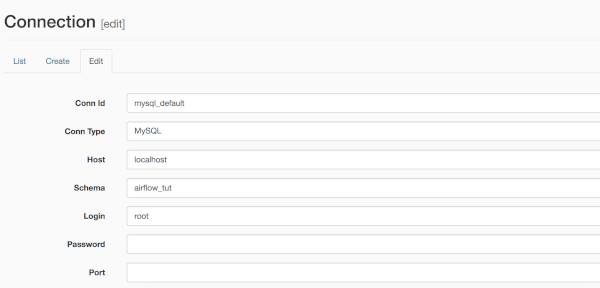
Per utilizzare la libreria MySQL dobbiamo importare MySqlHook
from airflow.hooks.mysql_hook import MySqlHook
def store_data(**kwargs):
ti = kwargs['ti']
parsed_records = ti.xcom_pull(key=None, task_ids='download_image')
connection = MySqlHook(mysql_conn_id='mysql_default')
for r in parsed_records:
url = r['url']
data = json.dumps(r)
sql = 'INSERT INTO recipes(url,data) VALUES (%s,%s)'
connection.run(sql, autocommit=True, parameters=(url, data))
return True
L’SQL della tabella è riportato di seguito:
CREATE TABLE recipes (
'id' int(11) UNSIGNED NOT NULL AUTO_INCREMENT,
'url' varchar(100) NOT NULL,
'data' text NOT NULL,
PRIMARY KEY (`id`)
);
Questo è tutto. Oh, aspetta… E’ possibile informare l’amministratore se il flusso di lavoro è stato eseguito correttamente? Airflow ci consente di utilizzare EmailOperator per tale scopo.
opr_email = EmailOperator(
task_id='send_email',
to='[email protected]',
subject='Airflow Finished',
html_content=""" <h3>DONE</h3> """,
dag=dag
)
Prima di usarlo dobbiamo apportare modifiche a airflow.cfg, nelle impostazioni relative alla posta. C’è una sezione [smtp].
[smtp]
# If you want airflow to send emails on retries, failure, and you want to use
# the airflow.utils.email.send_email_smtp function, you have to configure an
# smtp server here
smtp_host = smtp.gmail.com
smtp_starttls = False
smtp_ssl = True
# Uncomment and set the user/pass settings if you want to use SMTP AUTH
smtp_user = [email protected]
smtp_password = your_password
smtp_port = 465
smtp_mail_from = [email protected]
Conclusione
In questo post, abbiamo visto come introdurre Airflow nella nostra architettura di scraping esistente e come utilizzare MySQL con Airflow. Ci sono varie possibilità per migliorarlo o estenderlo. Provate e fatemi sapere.
Il codice è disponibile su Github
Quando eseguiamo i web scraping, c’è un’alta probabilità di essere bloccato e non abbiamo altra scelta che aspettare e pregare di essere sbloccati. Gli indirizzi IP proxy vengono utilizzati per evitare tali circostanze.