Per la stragrande maggioranza delle API REST Python che ho creato, ho usato Flask o Django. Questi due framework hanno costituito le fondamenta delle API REST di Python da ormai molti anni. Di recente, tuttavia, sono emersi alcuni nuovi strumenti. Uno di questi framework ha suscitato un notevole clamore: FastAPI. In questo articolo esploreremo alcune funzionalità di questo strumento.
Il progetto
La prima cosa da fare è elaborare un nuovo progetto. Volevo trovare un progetto che fosse interessante ma semplice, un progetto che mi permettesse di sperimentare il flusso di lavoro di FastAPI evitando dettagli confusi. Dopo averci pensato un po’, ho deciso di creare un’API REST per la finanza.
Questo progetto sarà composto da due parti:
- Un web scraper per ottenere dati finanziari e,
- Un’API REST che offre l’accesso ai dati.
Pertanto, ho diviso questo articolo in due. Sentiti libero di saltare intorno alle parti che trovi più interessanti.
Il setup
Prima di iniziare, dovremmo occuparci della parte più divertente dell’avvio di un nuovo progetto: la creazione del nostro ambiente. Sì, che divertimento!
Useremo alcune librerie, quindi consiglio di creare un nuovo ambiente virtuale.
Ecco un elenco di dipendenze che utilizzeremo:
- FastAPI (ovviamente è nel titolo!)
- Uvicorn
- Requests
- BeautifulSoup4
Possiamo eseguire un comando per installarli tutti in una volta:
pip install fastapi uvicorn requests beautifulsoup4
Per fortuna, questo è sufficiente per la configurazione. Immergiamoci subito nel codice!
Parte I: Il Web Scraper
Quando costruiamo un web scraper, dobbiamo prima di tutto rispondere a tre domande: dove , cosa e come.
Dove?
Esistono diverse risorse online dove è possibile trovare dati finanziari. Uno di questi è Yahoo Finance. Questo sito Web ha una pletora di dati finanziari organizzati per azienda e quindi per categoria. Useremo Yahoo Finance come obiettivo del nostro scraping.
Cosa?
Per ogni società quotata su Yahoo Finance, esiste una sezione riepilogativa. Questa sezione è ciò che utilizzeremo per ottenere i nostri dati.
Come?
Rispondere ai quesiti “dove” e “cosa” è piuttosto semplice, ma rispondere alla domanda “come” richiede un po’ di lavoro. Affronteremo questa domanda nelle seguenti sezioni.
Trovare il selettore CSS di un elemento.
Se apriamo Yahoo Finance e scegliamo un titolo, apparirà la pagina di riepilogo predefinita. Vogliamo raschiare il prezzo corrente del titolo e tutto nella tabella riepilogativa (tutto da “Chiusura precedente” a “Stima target 1A”).
Per lo scraping di questi dati, dobbiamo trovare il selettore CSS di ciascun elemento. Possiamo farlo tramite:
- Aprire gli strumenti di sviluppo di Chrome premendo F12.
- Premere Ctrl + Maiusc + C per abilitare il selettore di elementi.
- Evidenziare e fare clic su un elemento. Questo evidenzierà l’HTML dell’elemento nel pannello Elementi.
- Fare clic con il pulsante destro del mouse sull’HTML nel pannello Elementi e selezionare Copia > Copia selettore.
Per ciascuno dei nostri elementi desiderati, ripetiamo i passaggi 3 e 4.
Il file ‘scrape.json’
Una volta che abbiamo determinato i selettori CSS per ogni elemento, dobbiamo posizionarli in un posto utile. Per questo, creeremo un file chiamato scrape.json.
Alla fine, vogliamo archiviare i nostri dati in un dizionario Python. Per fare ciò, dobbiamo mappare le chiavi sui valori. In altre parole, dobbiamo sapere quali dati sono associati a quale chiave. scrape.json implementa questa mappatura.
La struttura di scrape.json è la seguente:
{
"elements": [
{
"from": "",
"to": ""
},
{
"from": "",
"to": ""
},
{
"from": "",
"to": ""
}
]
}
Ogni oggetto JSON in elements ha due attributi: from e to.
fromè il selettore CSS di un elemento di cui vogliamo i dati.toè la chiave con cui verranno archiviati i dati di questo elemento.
Di seguito il scrape.json compilato:
{
"elements": [
{
"from": "[class='Trsdu\\(0\\.3s\\) Fw\\(b\\) Fz\\(36px\\) Mb\\(-4px\\) D\\(ib\\)']",
"to": "price"
},
{
"from": "[data-test='PREV_CLOSE-value'] [class]",
"to": "prev_close"
},
{
"from": "[data-test='OPEN-value'] [class]",
"to": "open"
},
{
"from": "[data-test='BID-value'] [class]",
"to": "bid"
},
{
"from": "[data-test='ASK-value'] [class]",
"to": "ask"
},
{
"from": "[data-test='DAYS_RANGE-value']",
"to": "days_range"
},
{
"from": "[data-test='FIFTY_TWO_WK_RANGE-value']",
"to": "52_week_range"
},
{
"from": "[data-test='TD_VOLUME-value'] [class]",
"to": "volume"
},
{
"from": "[data-test='AVERAGE_VOLUME_3MONTH-value'] [class]",
"to": "avg_volume"
},
{
"from": "[data-test='MARKET_CAP-value'] [class]",
"to": "market_cap"
},
{
"from": "[data-test='BETA_5Y-value'] [class]",
"to": "beta"
},
{
"from": "[data-test='PE_RATIO-value'] [class]",
"to": "pe"
},
{
"from": "[data-test='EPS_RATIO-value'] [class]",
"to": "eps"
},
{
"from": "[data-test='EARNINGS_DATE-value']",
"to": "earnings_date"
},
{
"from": "[data-test='DIVIDEND_AND_YIELD-value']",
"to": "dividend_and_yield"
},
{
"from": "[data-test='EX_DIVIDEND_DATE-value'] span",
"to": "ex_dividend_yield"
},
{
"from": "[data-test='ONE_YEAR_TARGET_PRICE-value'] [class]",
"to": "target_est"
}
]
}
Codificare lo scraping.
Dopo aver compilato il file scrape.json con le nostre mappature, è il momento di codificare lo scraper.
Ci sono quattro passaggi che il nostro scraper deve compiere:
- Creare un URL che punti alla pagina web di Yahoo Finance del titolo
- Scaricare la pagina web
- Analizzare la pagina web
- Estrarre e mappare i dati desiderati (Sì, so cosa stai pensando, tecnicamente sono due passaggi. Non possiamo essere tutti perfetti.)
Diamo un’occhiata al codice e poi lo esaminiamo sezione per sezione.
import requests
from bs4 import BeautifulSoup
class Scrape():
def __init__(self, symbol, elements):
url = "https://finance.yahoo.com/quote/" + symbol
r = requests.get(url)
if(r.url != url): # redirect occurred; likely symbol doesn't exist or cannot be found.
raise requests.TooManyRedirects()
r.raise_for_status()
self.soup = BeautifulSoup(r.text, "html.parser")
self.__summary = {}
for el in elements["elements"]:
tag = self.soup.select_one(el["from"])
if tag != None:
self.__summary[el["to"]] = tag.get_text()
def summary(self):
return self.__summary
Nella riga 7 (fase 1) si costruisce un URL.
Nella riga 9 (fase 2) sta scaricando la pagina web del titolo azionario.
Nelle righe 10-13 si controlla se si sono verificati errori o reindirizzamenti durante la fase 2. Se si è verificato un reindirizzamento, significa che il simbolo di borsa non esiste o non è corretto; trattiamo questo scenario come un errore.
Nella riga 15 (fase 3) si analizza la pagina web.
Nelle righe 17-23 (fase 4) è dove avviene la magia. Qui, le mappature in scrape.json sono usate per costruire un dizionario, __summary. Ogni elemento è selezionato con self.soup.select_one(el["from"]). Ai dati dell’elemento (testo) viene quindi assegnata una chiave con self.__summary[el["to"]] = tag.get_text().
Da buoni programmatori che siamo, dovremmo testare il nostro codice prima di continuare. Creiamo main.py e aggiungiamo il seguente codice di test:
from Scrape import Scrape
import json
elements_to_scrape = {}
f = open("scrape.json")
data = f.read()
f.close()
elements_to_scrape = json.loads(data)
s = Scrape("AAPL", elements_to_scrape)
print(s.summary())
Con un po’ di fortuna, dovremmo vedere un dizionario Python popolato con la stampa dei dati sullo schermo. Questo è tutto per il web scraper! Ora possiamo cambiare marcia e iniziare a lavorare sulla nostra API REST.
Parte II: L’API REST
L’idea di base della nostra API REST sarà la seguente:
- La nostra API REST avrà un endpoint, che prenderà un simbolo di borsa come input.
- Il nostro scaper utilizzerà il simbolo per raccogliere i dati di riepilogo finanziario del titolo.
- L’endpoint restituirà i dati di riepilogo in formato JSON.
Ora che abbiamo l’idea di base, iniziamo a programmare.
Configurazione FastAPI
FastAPI è facile da eseguire. Aggiungiamo il seguente codice a main.py:
from fastapi import FastAPI
app = FastAPI()
@app.get("/root")
def root():
return "Hello World!"
Per avviare FastAPI, possiamo emettere il seguente comando:
uvicorn main:app --reload
Analizziamo questo comando:
main: si riferisce al nostro filemain.py.app: si riferisce all’app FastAPI creata conmain.pyla lineaapp = FastAPI().--reload: indica al server di riavviarsi quando ha rilevato modifiche al codice.
A parte: uvicorn è un’interfaccia ASGI (Asynchronous Server Gateway Interface) veloce che FastAPI utilizza per l’esecuzione. Non approfondiremo l’uvicorn, ma se sei interessato a saperne di più, puoi controllare il loro sito web .
Ora che abbiamo avviato il server, possiamo andare su http://127.0.0.1:8000/docs. Qui troveremo la documentazione dell’API interattiva automatica. Possiamo utilizzare questo strumento per verificare la corretta funzionalità dei nostri endpoint. Poiché al momento abbiamo solo l’endpoint root, non c’è molto da testare. Iniziamo con le modifiche.
Definizione di un endpoint
Il passaggio successivo consiste nell’aggiungere l’endpoint di riepilogo. Come accennato in precedenza, prenderà un simbolo azionario e restituirà il foglio di riepilogo finanziario di quel titolo.
Aggiungiamo questo codice in main.py
@app.get("/v1/{symbol}/summary/")
def summary(symbol):
summary_data = {}
try:
s = Scrape(symbol, elements_to_scrape)
summary_data = s.summary()
except TooManyRedirects:
raise HTTPException(status_code=404,
detail="{symbol} doesn't exist or cannot be found.")
except HTTPError:
raise HTTPException(status_code=500,
detail="An error has occurred while processing the request.")
return summary_data
Qui, definiamo un endpoint in /v1/{symbol}/summary/. Si usa {symbol} per denotare un parametro di percorso. Questo parametro viene passato al nostro metodo endpoint e quindi nella nostra istanza dell’oggetto Scrape, s. Assegniamo quindi a summary_datail il risultato di s.summary(). Se non si verificano eccezioni, si restituisce summary_data.
NOTA: il tipo di contenuto predefinito di FastAPI è application/JSON. Poiché s.summary() restituisce un oggetto dizionario, FastAPI lo converte automaticamente in JSON. Quindi, non è necessario eseguire questa conversione manualmente.
FastAPI ci consente di definire un metodo di start-up, che ovviamente verrà eseguito all’avvio del nostro server. Quindi si trasferisce il nostro codice di caricamento scrape.json, da testing, all’interno di questo metodo.
@app.on_event("startup")
def startup():
f = open("scrape.json")
data = f.read()
f.close()
global elements_to_scrape
elements_to_scrape = json.loads(data)
È buona norma inserire metodi più lenti e utilizzabili una tantum nella funzione di avvio. In questo modo, evitiamo di rallentare i nostri tempi di risposta eseguendo codice non necessario durante una richiesta.
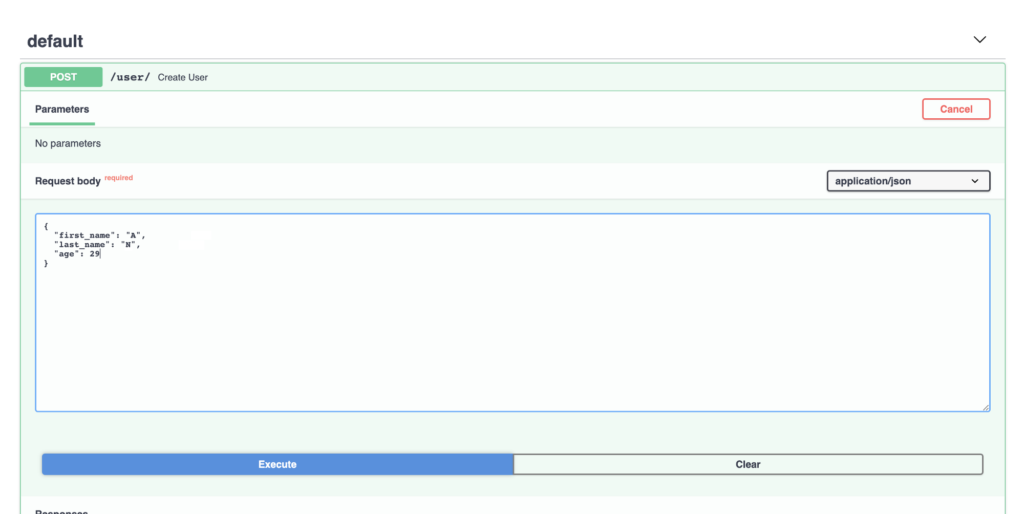
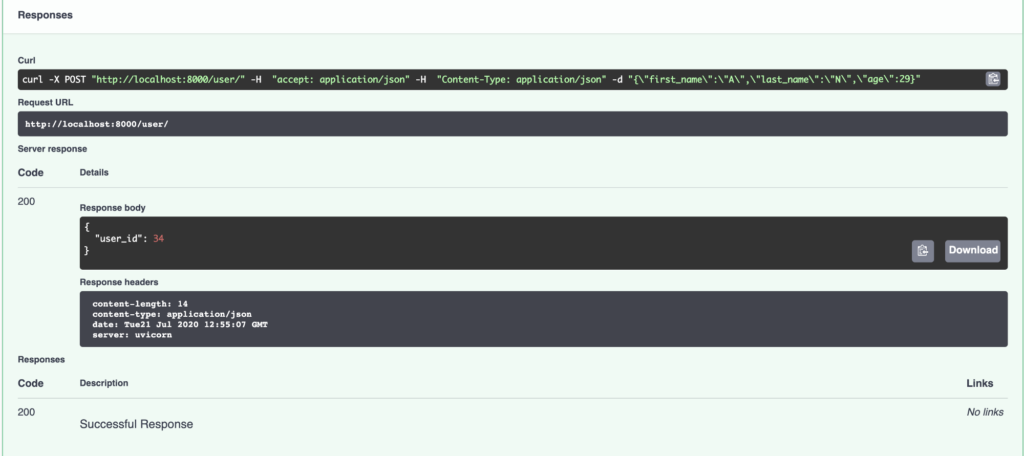
A questo punto, dovremmo avere un API REST funzionante. Possiamo testarlo tornando allo strumento endpoint e digitando un titolo.
{
"price": "135.37",
"prev_close": "135.13",
"open": "134.35",
"bid": "135.40 x 1000",
"ask": "135.47 x 1300",
"days_range": "133.69 - 135.51",
"52_week_range": "53.15 - 145.09",
"volume": "60,145,130",
"avg_volume": "102,827,562",
"market_cap": "2.273T",
"beta": "1.27",
"pe": "36.72",
"eps": "3.69",
"earnings_date": "Apr 28, 2021 - May 03, 2021",
"dividend_and_yield": "0.82 (0.61%)",
"ex_dividend_yield": "Feb 05, 2021",
"target_est": "151.75"
}
Filtraggio
Tecnicamente, abbiamo realizzato tutto ciò che ci eravamo prefissati di fare. Tuttavia, c’è un punto di attenzione. Ogni volta che richiediamo un riepilogo delle scorte, viene restituito l’intero foglio di riepilogo. E se volessimo solo pochi punti dati selezionati? Sembra un terribile spreco richiedere un intero oggetto riassuntivo quando sono necessari solo pochi punti dati. Per risolvere questo problema, dobbiamo implementare un filtro. Fortunatamente, FastAPI offre una soluzione: le query.
Per aggiungere il filtro, è necessario modificare il metodo summary dell’endpoint per gestire le query. Ecco come farlo:
@app.get("/v1/{symbol}/summary/")
def summary(symbol, q: Optional[List[str]] = Query(None)):
summary_data = {}
try:
s = Scrape(symbol, elements_to_scrape)
summary_data = s.summary()
if(q != None):
# if all query parameters are keys in summary_data
if all (k in summary_data for k in q):
# summary_data keeps requested key-value pairs
summary_data = {key: summary_data[key] for key in q}
# else, return whole summary_data
except TooManyRedirects:
raise HTTPException(status_code=404, detail="{symbol} doesn't exist or cannot be found.")
except HTTPError:
raise HTTPException(status_code=500, detail="An error has occurred while processing the request.")
return summary_data
l parametro q: Optional[List[str]] = Query(None) dice a FastAPI che dovrebbe aspettarsi, facoltativamente, come query una List di String.
Le righe 8 e 9 controllano le stringhe di query rispetto a tutte le chiavi nel dizionario summary_dat. Se anche i parametri della query sono chiavi, manteniamo solo quelle coppie chiave-valore. In caso contrario, se uno dei parametri della query non è una chiave, viene restituito l’intero oggetto.
NOTA: per fare pratica, è possibile modificare la funzionalità del metodo precedente per restituire solo le coppie chiave-valore dei parametri di query valide. Puoi anche scegliere di sollevare un’eccezione se un parametro di query non corrisponde a nessuna delle chiavi.
Testiamo il nostro nuovo codice interrogando solo price e open.
{
"price": "135.37",
"open": "134.35"
}
Conclusione
In questo articolo abbiamo creato un web scraper per recuperare i dati finanziari da Yahoo Finance durante questo articolo e abbiamo creato un API REST per servire questi dati. È dannatamente buono, e dovremmo essere orgogliosi di noi stessi.
Comunque per oggi è tutto. Come sempre, tutto il codice può essere trovato sul mio GitHub.
Grazie per aver letto. Spero che tu abbia imparato qualcosa e ti sia divertito!
Ci vediamo tutti la prossima volta.
Riferimenti
[1] Documentazione Beautiful Soup – https://www.crummy.com/software/BeautifulSoup/bs4/doc/
[2] FastAPI – https://fastapi.tiangolo.com/
[3] Requests: HTTP for HumansTM – https://2.python-requests.org/en/master/
[4] Uvicorn – https://www.uvicorn.org/
[5] Yahoo Finance – https://finance.yahoo.com/


![scienzadeidati articoli - Database con FASTAPI [Parte2]](https://scienzadeidati.com/storage/jupiterx/images/scienzadeidati-articoli-Database-con-FASTAPI-Parte2-75a4ee3.jpg)