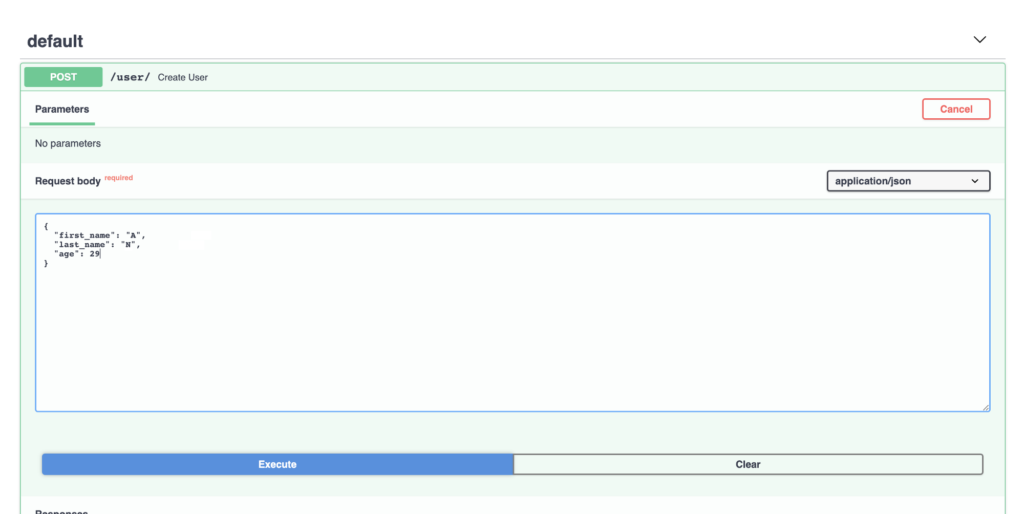
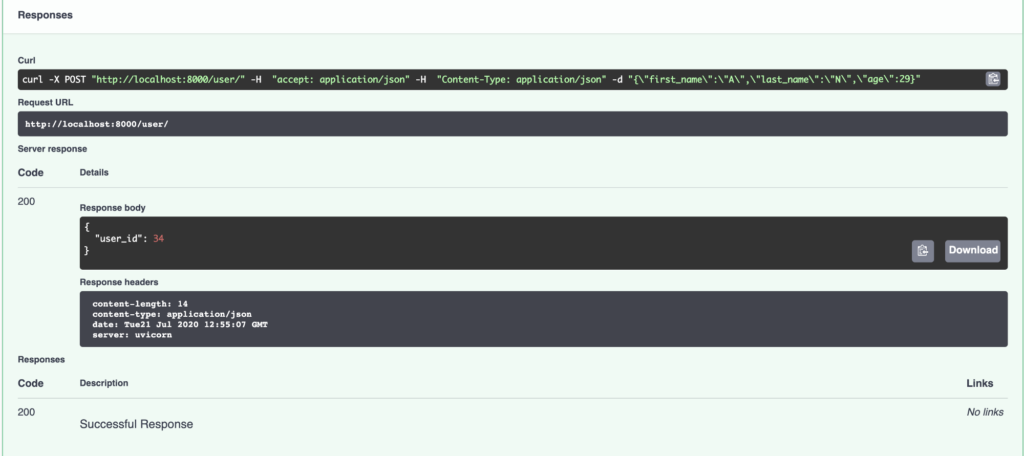
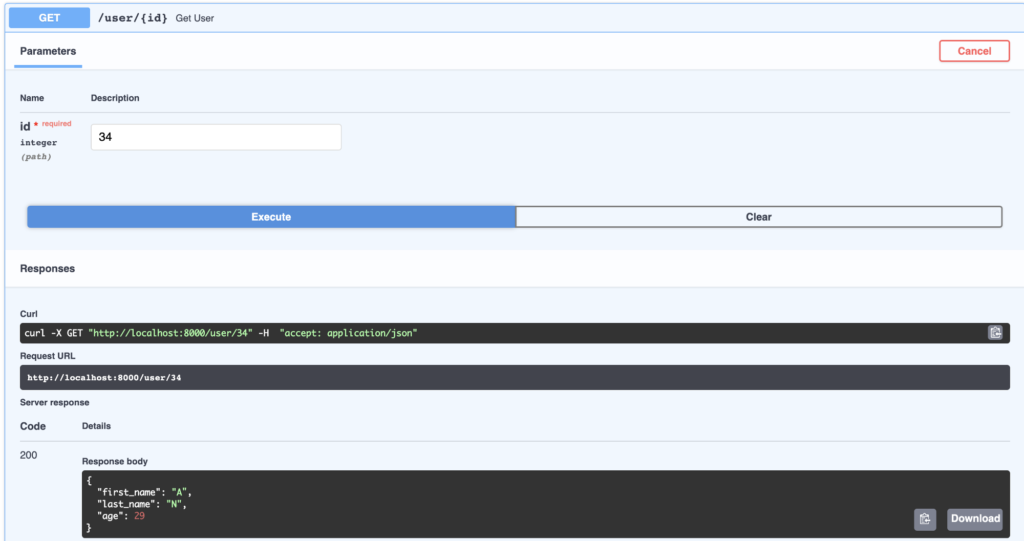
In questo post vediamo il primo passo per sviluppare un’infrastruttura di analisi per ricercare adeguatamente le dinamiche del mercato delle criptovalute, la raccolta e l’archiviazione dei dati.
La Microstruttura di mercato è un settore dell’Economia e della Finanza che studia le dinamiche dei mercati finanziari, concentrandosi sugli attori (market maker, speculatori e retail trader) e sulla struttura degli scambi (frammentazione, Dealer vs LOB e trasparenza del mercato).
I dati di cambio tendono a contenere enormi quantità di dati sul trading e sul orderbook (libro degli ordini). Per raccogliere questi dati in modo efficace, dovremo creare un sistema affidabile per gestire dati ad alta frequenza e quantità di dati su larga scala.
Una settimana di dati di trading per un asset può facilmente raggiungere centinaia di milioni di punti dati all’interno di un unico scambio. Sottolineo che non entriamo nei dettagli tecnici relativi a ClickHouse e Kafka. Forniamo solo una spiegazione introduttiva del motivo per cui questi strumenti sono stati selezionati. La priorità di questo articolo è mostrare come costruire dall’inizio alla fine un sistema di raccolta e archiviazione di dati di criptovalute.
Durante il tutorial sono forniti collegamenti per una comprensione più approfondita degli strumenti.
Dove archiviare enormi set di dati? Presentazione di ClickHouse
ClickHouse è un sistema di database basato su colonne creato per aggregare facilmente milioni di punti dati in pochi millisecondi. ClickHouse è un database OLAP (elaborazione analitica online), ciò significa che ClickHouse è specializzato in un’elevata produttività di insert, insert da centinaia di migliaia a milioni di righe alla volta, anziché singoli insert. Il vantaggio è che ClickHouse avrà una velocità impareggiabile per l’analisi, ma non potrà supportare singoli insert continui. È qui che entra in gioco Kafka.
Come produrre un’elevata produttività? Presentazione di Kafka
Apache Kafka è un sistema distribuito di messaggistica di pubblicazione-sottoscrizione progettato per un elevato throughput. Quando si raccolgono dati di trading ad alta frequenza, è fondamentale disporre di uno strumento che possa essere veloce, tollerante ai guasti e scalabile. Kafka soddisfa tutte queste esigenze ed è realizzato da una combinazione ben equilibrata di produttori, consumatori e intermediari.
Gli intermediari, i broker fungono da tramite tra i produttori (invio di dati) e i consumatori (ricezione di dati). I broker lo fanno archiviando i messaggi in argomenti, diversi tipi di messaggi, come transazioni, dati Iot, tracciamenti, ecc. L’argomento è ciò che determina il percorso dal produttore al consumatore.
Da dove ottenere i dati? Presentazione di CryptoFeed
Cryptofeed, creata da Bryant Moscon, è una libreria Python che utilizza asyncio e WebSocket per fornire feed di trade di criptovaluta da un’ampia varietà di exchange. Con Cryptofeed, è possibile aggiungere più flussi di dati da exchange di cryptovalute in un feed unificato. Cryptofeed fornisce molti esempi di come può essere integrato con più backend, incluso Kafka.
Configurazione di Kafka e ClickHouse con Docker
Ora è il momento di realizzare il nostro sistema di raccolta e archiviazione dei dati, utilizzando ClickHouse per l’archiviazione di dati di massa e Kafka per un’efficace acquisizione dei dati in ClickHouse. Per una facile riproducibilità e distribuzione, tutto questo sarà inserito all’interno di containers di Docker,
Step 1: installazione di Docker e Docker Compose
Utilizziamo Docker per la distribuzione di ClickHouse e Kafka, quindi ti consiglio di avere l’ambiente Docker già installato prima di continuare.
Step 2: Creazione del Docker Compose per Clickhouse-Kafka
Il primo passo è creare una directory in cui memorizzare i nostri file docker, il file dei requisiti e il nostro main.py. In questo tutorial è denominata CryptoDB.
Dopo essere entrati nella directory, creiamo un file docker-compose.yml e modifichiamo il file di composizione come di seguito. Descriviamo ogni passaggio in dettaglio.
version: '3.9'
services:
clickhouse-server:
image: yandex/clickhouse-server
ports:
- "8123:8123"
- "8124:9000"
volumes:
- clickhouse-volume:/var/lib/clickhouse
cryptofeed:
build:
context: .
dockerfile: Dockerfile
volumes:
- ./:/app
depends_on:
- zookeeper
- kafka
zookeeper:
image: wurstmeister/zookeeper:3.4.6
expose:
- "2181"
kafka:
image: wurstmeister/kafka:2.11-2.0.0
depends_on:
- zookeeper
ports:
- "9092:9092"
expose:
- "9093"
environment:
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
clickhouse-volume:
ClickHouse-Server: il servizio che crea il nostro database ClickHouse ed espone le porte 8123 e 9000 per HTTP/TCP. Tutti i dati verranno archiviati su un volume denominato, clickhouse-volume.
Zookeeper: necessario per la gestione dei nodi Kafka
Kafka: Il servizio crea il nostro nodo Kafka. Le variabili ambientali sono essenziali per il corretto funzionamento di Kafka e cambieranno in base alla posizione in cui si sta ospitando Kafka. Questo tutorial fornisce un’ottima spiegazione sul significato di queste variabili ambientali. Nel complesso, la maggior parte delle variabili ambientali determina il modo in cui Kafka comunica con altri servizi. La porta principale utilizzata da Kafka è la porta 9092.
CryptoFeed: crea un ambiente Python ed esegue main.py per creare i nostri produttori/argomenti Kafka e avviare connessioni WebSocket.
Dopo aver preparato il nostro Docker-compose, possiamo effettuare l’ultimo step prima di avviare i contenitori: scrivere lo script di cryptofeed e configurare il dockerfile di CryptoFeed.
Preparazione dello script CryptoFeed
Step 1: scrittura dello script CryptoFeed
Prima di utilizzare i motori di ClickHouse e Kafka, dobbiamo creare uno script utilizzando CryptoFeed in modo da definire come strutturare le nostre tabelle in ClickHouse. Raccogliamo i dati di trading di BTCUSD e i dati del book degli ordini limite di livello 2 da due exchanges di criptovalute. BitFinex cattura circa il 3,5% del volume totale in 24 ore in tutto il mondo e Binance ne cattura circa il 25,5%. Selezioniamo questi due exchange per catturare dinamiche interessanti grazie alla grande frammentazione dei mercati delle criptovalute. Enormi exchange come Binance possono avere un comportamento microstrutturale di mercato unico rispetto a exchange più piccoli, come BitFinex.
from cryptofeed import FeedHandler
from cryptofeed.backends.kafka import BookKafka, TradeKafka
from cryptofeed.defines import L2_BOOK, TRADES, L3_BOOK
from cryptofeed.exchanges import Coinbase, Binance, Bitfinex
def main():
f = FeedHandler()
HOSTNAME = 'kafka'
cbs = {TRADES: TradeKafka(bootstrap=HOSTNAME), L2_BOOK: BookKafka(bootstrap=HOSTNAME), L3_BOOK: BookKafka(bootstrap=HOSTNAME)}
# Add trade and lv 2 bitcoin data to Feed
f.add_feed(Bitfinex(max_depth=25, channels=[TRADES, L2_BOOK], symbols=['BTC-USD'], callbacks=cbs))
f.add_feed(Binance(max_depth=25, channels=[TRADES, L2_BOOK], symbols=['BTC-BUSD'], callbacks=cbs))
# Example of how to extract level 3 order book data
# f.add_feed(Coinbase(max_depth=25, channels=[TRADES, L2_BOOK, L3_BOOK], symbols=['BTC-USD'], callbacks=cbs))
f.run()
if __name__ == '__main__':
main()
Nota: il nome dell’host deve essere lo stesso del servizio Kafka specificato nel file docker-compose, altrimenti l’impostazione predefinita prevede l’utilizzo di ‘localhost’. Localhost non funziona nel nostro approccio multi-container.
Aggiungiamo un feed al nostro gestore di feed, che si collegherà alle API del nostro exchange tramite websocket e quindi invierà i dati di trading tramite i produttori Kafka ai nostri broker Kafka che memorizzano i nostri argomenti. CryptoFeed crea il proprio produttore e argomento Kafka quando utilizza TradeKafka e BookKafka.
Ci sarà un argomento unico per ogni canale, exchange e simbolo, quindi in totale creiamo 4 argomenti corrispondenti a 2 exchange (Binance e BitFinex), 2 canali (TRADES e L2_BOOK) e un simbolo (BTC-USD).
La struttura degli argomenti sono:
<channel>-<EXCHANGE>-<SYMBOL> (es. trade-COINBASE-BTC-USD)
Abbiamo anche inserito un esempio di codice per aggiungere i dati del orderbook di livello tre da CoinBase, ma commentato. Sentiti libero di esplorare CryptoFeed , ma tieni presente che in questo articolo non descriviamo come raccogliere i dati dell’orderbook di livello 3.
Dato che utilizziamo i dati del book L2 e dei dati di trade, la struttura delle tabelle finali è simile a questa.
Trades: {feed, symbol, timestamp, receipt_timestamp, side, amount, price, order_type, id}
Book: {timestamp, receipt_timestamp, delta, bid[0–25], ask[0–25], _topic}
Sia il lato bid che quello ask dell’order book avranno una profondità massima di 25 livelli di prezzo.
Un’ulteriore colonna _topic, l’argomento Kafka, viene aggiunta alla tabella del orderbook perché i dati originali non contengono l’exchange e il simbolo. _topic verrà utilizzato come metodo di filtraggio per analisi successive.
Step 2: Creazione del dockerfile di CryptoFeed
Affinché lo script CryptoFeed possa essere eseguito sul nostro container, abbiamo bisogno di un ambiente Python con tutti i pacchetti necessari, possiamo creare l’ambiente che desideriamo. Di seguito descriviamo come crearlo.
FROM python:3.7-slim
WORKDIR /app
COPY . .
# upgrade pip, install requirements and update permissions for main.py
RUN pip install --upgrade pip \
&& pip install -r ./requirements.txt \
&& chmod +x /app/main.py
# Create CryptoFeed Kafka Producers
CMD ["python", "/app/main.py"]
Il dockerfile utilizza solo un’immagine python slim standard, installa i requisiti ed esegue lo script main.py. Molto semplice.
I requisiti sono:
cryptofeed==1.9.3
aiokafka==0.7.2
A questo punto possiamo a far partire il docker compose con il seguente comando:
docker-compose -d
Quando tutti i container saranno operativi, i broker Kafka dovrebbero iniziare a raccogliere i dati degli exchange all’interno degli argomenti generati automaticamente.
Ora è il momento di conservarli a lungo termine.
Configurazione di Clickhouse e Kafka
Il passaggio successivo consiste nel creare i sottoscrittori/consumatori per acquisire e quindi archiviare i dati nelle tabelle ClickHouse. Abbiamo usato questa utile guida per la configurazione di Kafka-ClickHouse e descriviamo nel dettaglio di seguito.
Affinché una tabella ClickHouse raccolga dati da un argomento Kafka è necessario completare tre passaggi:
- Creare le tabelle finali MergeTree in ClickHouse per archiviare i dati per l’analisi a lungo termine
- Creare tabelle del motore Kafka per strutturare i dati degli argomenti nel formato ClickHouse
- Generare una vista materializzata per spostare i dati dalle tabelle del motore Kafka alle tabelle MergeTree
Step 1: creazione di tabelle MergeTree ClickHouse
Accediamo al server ClickHouse tramite CLI o tramite uno strumento di gestione database (es: Dbeaver e HouseOps).
Innanzitutto creiamo un nuovo database per archiviare le tabelle degli exchange di criptovalute
CREATE DATABASE CryptoCrypt
Quindi creiamo la tabella MergeTree dell’Orderbook L2 e la tabella MergeTree dei Trades. È molto importante usare il tipo corretto per ciascuna colonna. Guarda qui se hai bisogno di esplorare quali tipi usare.
CREATE TABLE CryptoCrypt.Trades (
feed String,
symbol String,
trade_date DateTime64(3),
receipt_timestamp DateTime64(3),
side String,
amount Float64,
price Float64,
order_type Nullable(String),
id UInt64
) Engine = MergeTree
PARTITION BY toYYYYMM(trade_date)
ORDER BY (feed, trade_date);
CREATE TABLE CryptoCrypt.L2_orderbook (
trade_date DateTime64(3),
receipt_timestamp DateTime64(3),
delta Int8,
bid Map(String, String),
ask Map(String, String)
) Engine = MergeTree
PARTITION BY toYYYYMM(trade_date)
ORDER BY (trade_date);
ALTER TABLE CryptoCrypt.L2_orderbook
ADD COLUMN _topic String
Una cosa importante da notare per la tabella L2_orderbook è la complessità per memorizzare i bid e gli ask. Il tipo di mappa deve essere in grado di memorizzare i dati {price:volume} a una profondità di 25 livelli. La mappa non supporta i tipi float, quindi per preservare quei dati la chiave del prezzo e il valore del volume devono essere archiviati come stringhe. I tipi possono essere facilmente riportati alla normalità nella fase di elaborazione dei dati. Se prevediamo di utilizzare i dati L3, viene aggiunto un ulteriore livello di complessità perché dovremmo annidare le colonne bid e ask per memorizzare le sotto-colonne di ID ordine, prezzo e coppie di volume.
Infine dobbiamo evidenziare che per aggiungere la colonna virtuale, _topic, è necessario aggiungere la colonna DOPO la creazione della tabella e prevedere tale colonna solo nella tabella MergeTree e non nella tabella Kafka.
Step 2: Creazione di tabelle nel motore Kafka
Creiamo le tabelle del motore Kafka con la stessa struttura delle tabelle MergeTree. Ogni tabella del motore Kafka sottoscrive due argomenti in base ai dati che sta raccogliendo (trades o orderbook) e un broker che memorizza l’argomento. A fini di test locali, il broker Kafka si trova in Kafka:9092. Poiché ClickHouse e Kafka condividono la stessa rete, possiamo utilizzare “Kafka” come host.
CREATE TABLE CryptoCrypt.trades_queue (
feed String,
symbol String,
trade_date DateTime64(3),
receipt_timestamp Float64,
side String,
amount Float64,
price Float64,
order_type Nullable(String),
id UInt64
) ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'trades-BINANCE-BTC-BUSD, trades-BITFINEX-BTC-USD',
kafka_group_name = 'trades_group1',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n';
CREATE TABLE CryptoCrypt.books_queue (
trade_date Float64,
receipt_timestamp Float64,
delta Int8,
bid Map(String, LowCardinality(Float64)),
ask Map(String, LowCardinality(Float64))
) ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092',
kafka_topic_list = 'book-BINANCE-BTC-BUSD, book-BITFINEX-BTC-USD',
kafka_group_name = 'trades_group1',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n';
Per avere maggiori dettagli sul funzionamento delle impostazioni di un motore Kafka, si può consultare questa guida. Inoltre, da notare come è stata risolta la complessità bid/ask utilizzando un trucco per assimilare la struttura dei dati {price: volume}. Poiché l’argomento archivia {prezzo:volume} come tipi {stringa:float}, è necessario utilizzare LowCardinality come soluzione alternativa per archiviare temporaneamente i dati prima che vengano inseriti in batch nella tabella MergeTree. Generalmente LowCardinality non è in grado di gestire enormi set di dati, ma in questo caso possiamo utilizzarlo poiché viene utilizzato solo per archiviare temporaneamente i dati in una tabella Kafka.
Step 3: Trasferire i dati tra tabelle con viste materializzate
L’ultimo passaggio consiste nel creare la vista materializzata che fungerà da meccanismo di inserimento tra le tabelle MergeTree e le tabelle Kafka. Possiamo osservare che la funzione cast viene utilizzata per convertire le colonne bid e ask nei corretti tipi di dati e viene richiesta la colonna virtuale _topic.
Non è necessario che le colonne virtuali siano già nella tabella Kafka per inserirle nella tabella MergeTree.
CREATE MATERIALIZED VIEW CryptoCrypt.trades_queue_mv TO CryptoCrypt.Trades AS
SELECT *
FROM CryptoCrypt.trades_queue;
CREATE MATERIALIZED VIEW CryptoCrypt.books_queue_mv TO CryptoCrypt.L2_orderbook AS
SELECT trade_date, receipt_timestamp, delta, cast(bid, 'Map(String, String)') as bid , cast(ask, 'Map(String, String)') as ask, _topic
FROM CryptoCrypt.books_queue;
Tramite le viste materializzate, i dati che erano stati archiviati negli argomenti inizieranno a essere archiviati nelle tabelle MergeTree finali.
Risoluzione dei problemi e test
Ora che il sistema di raccolta e archiviazione dei dati è in esecuzione, è tempo di verificare che tutto funzioni. Partiamo dai metodi di risoluzione dei problemi più semplici per rilevare i problemi e aumentare la complessità se il problema persiste.
Semplici controlli con ClickHouse
Possiamo verificare che tutte le tabelle siano state create e verificare se sono presenti dati nelle nostre tabelle MergeTree finali. Possiamo usare ClickHouse CLI o una console SQL su Dbeaver.
# Show all tables, should have 2 kafka, 2 MergeTree and 2 views
SHOW TABLES FROM CryptoCrypt
# Check count of MergeTree tables
SELECT COUNT() FROM CryptoCrypt.L2_orderbook
SELECT COUNT() FROM CryptoCrypt.Trades
# Check if data is correct format
SELECT * FROM CryptoCrypt.L2_orderbook LIMIT 5
SELECT * FROM CryptoCrypt.Trades LIMIT 5
# If no data in MergeTree tables check Kafka tables
SELECT * FROM CryptoCrypt.books_queue LIMIT 5
SELECT * FROM CryptoCrypt.trades_queue LIMIT 5
Se non ci sono dati nelle tabelle Kafka, è probabile che sia dovuto a un problema del produttore Kafka oppure una delle colonne è stata digitata in modo errato. Se viene visualizzato un ‘cannot parse error‘ è probabilmente che sia presente una errata digitazione, in caso contrario è probabilmente dovuto all’utilizzo di un erratto elenco di broker Kafka durante la creazione delle tabelle Kafka.
E’ necessario assicurarsi sempre che l’elenco di broker Kafka = ascoltatori pubblicati da Kafka.
Controllo dei broker e degli argomenti di Kafka
Se i problemi di cui sopra non si verificavano per la mancanza di dati nelle tabelle, è tempo di verificare se sono presenti dati archiviati nei topic. Per verificare se i topic sono stati creati e se stanno memorizzando dei dati possiamo accedere alla bash del contenitore docker di Kafka ed eseguire alcuni comandi
# From your terminal run: MAKE SURE TO SET KAFKA CONTAINER NAME
> docker exec -i -t -u root $(docker ps | grep NAME_OF_KAFKA_CONTAINER | cut -d' ' -f1) /bin/bash
# List all topics
bash> $KAFKA_HOME/bin/kafka-topics.sh --list --bootstrap-server kafka:9092
# Check if a topic is collecting messages
bash> $KAFKA_HOME/bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic book-BITFINEX-BTC-USD --from-beginning
Se tutto funziona correttamente, nel terminale vediamo tutti e quattro i topic, insieme a migliaia di messaggi al secondo. Mentre se vediamo i nostri dati, è necessario tornare alla risoluzione dei problemi di ClickHouse e controllare i log, altrimenti è il momento di controllare i produttori Kafka e le connessioni WebSocket.
Controllo dei log di CryptoFeed
Se non abbiamo dati nei topic, è il momento di controllare i registri di CryptoFeed. Il gestore del feed produce i log all’avvio di main.py, che mostra se le connessioni WebSocket sono riuscite e se si sono verificati errori durante la produzione dei produttori Kafka. Questi registri sono archiviati nella stessa directory del file del docker-compose.
Nota: LEADER_NOT_AVAILABLE è un errore comune che si verifica a causa di un host broker improprio. Se vogliamo separare ClickHouse e Kafka in diverse macchine host, questo sarà un probabile errore. Questo link descrive come si verifica l’errore e come risolverlo.
Conclusione
Questo tutorial copre il primo e più essenziale passaggio nella creazione di una piattaforma di analisi delle criptovalute, il sistema di raccolta e archiviazione dei dati. Senza i dati è come costruire una casa con un martello e senza chiodi. Inoltre, con un sistema ClickHouse-Kafka (e molto spazio di archiviazione), possiamo facilmente archiviare i dati di trading delle criptovalute da dozzine di diverse exchange. Il passaggio successivo consiste nel preelaborare i dati con Apache Spark per prepararci alla creazione di modelli di previsione (LSTM e XGBoost) e di inferenza causale, insieme ad alcune analisi esplorative, al fine di ottenere una visione approfondita della microstruttura del mercato degli exchange di criptovalute.









![scienzadeidati articoli - Database con FASTAPI [Parte2]](https://scienzadeidati.com/storage/jupiterx/images/scienzadeidati-articoli-Database-con-FASTAPI-Parte2-75a4ee3.jpg)